
Live Response is the process of collecting data from compromised endpoints for an investigation while those assets remain active. Collecting Live Response data is critical to a successful incident response investigation. As Endpoint Detection and Response (EDR) and Antivirus (AV) have grown in capability, so too have attackers. To protect your environment and keep your network safe, you must be able to collect volatile data in a repeatable, defensible, and efficient way. A blue team will live and die by their ability to collect, analyze, and understand data. Likewise, the data that you collect drives your ability to respond to complex threats.
Why Perform Live Response?
There are no hard and fast rules for performing a Live Response, but there are a few guidelines to follow and caveats you should be aware of. Ultimately, the decision of whether to perform a live response often comes down to time, cost, and expertise, but there are a few compelling reasons that can shift the scale.
The first is the fallibility of “wipe and reset.” We’ve worked with many organizations whose default IR strategy is to wipe and reset compromised machines. This is treating the symptoms in most cases and not addressing the sickness as it doesn’t always assist in fixing the root cause. It does not help to wipe, reset, and upgrade the machine if the initial access vector was a compromised credential.
One other reason that we’ve heard stated for not incorporating live response is, “We have EDR – that’s got enough telemetry, right?”. The answer is almost always “maybe.” You probably don’t have 100% coverage of everything. If you don’t supplement your Endpoint Detection and Response (EDR) logs with Windows Event logs you are missing a ton of data, that might help you prevent future incidents. Your EDR may log some scheduled task activity, but only alert on schtasks.exe. What if a scheduled task was registered by directly modifying the API? Windows Event Log ID 4698 has your back.
The last reason to do a Live Response is due to the risk of data loss when performing other forensic methods. Methods such as dead disk forensics can delete evidence and wipe temporary files. Additionally, Live Response collection permits you to collect memory data, where dead disk forensics has no such provisions.
When to Collect Live Response Data
When do you collect the data? As soon as possible after a cybersecurity incident. The sooner you collect the data, the less time it has to be modified, overwritten, or lost. I always recommend collecting triage information for affected hosts, and if possible, collecting memory information as well. Another consideration is when you will contain the device. You should consider the operational impact that leaving an affected device online will have. It’s possible that malware could continue spreading or ransomware could continue encrypting. You may want to consider quarantining the device and leaving it online to perform a Live Response.
How to Collect Live Response Data
The first step in running a Live Response is to collect evidence. We at Praetorian like to use Brimor Labs’ Live Response tool. This tool collects volatile host data from Windows, macOS, and *nix based operating systems. There are many alternatives, and most work well. A critical factor is to pick a tool and stick with it. Practice with it, have a copy ready to be deployed to individual machines, understand its effect on the system, and familiarize yourself with its limitations. Doing this ahead of time will help to make your response repeatable and predictable.
Pitfalls to Avoid
Regardless of which tool you pick, there are several pitfalls that you will want to avoid. RFC 3227 – Guidelines for Evidence Collection and Archiving https://datatracker.ietf.org/doc/html/rfc3227 from 2002 outlines a few pitfalls that are still relevant almost 20 years later:
Premature Shutdown
The first response action you want to avoid is prematurely shutting down the system. Don’t shut down the system before collecting evidence. Running processes, temporary files and folders, and many other artifacts could be deleted.
Failing to Protect your Tools
Second, don’t trust the system you’re investigating. Run your tool from an external source. Ideally, use a CD or DVD so your tool can’t be overwritten or modified (alternatively, if you don’t have any ancient tech lying around, SD cards with write protection, USB media and network shares are valid options).
Modifying the System
You don’t want the system affecting your tools, you also don’t want your tools affecting the system. Don’t run anything that can clobber timestamps (e.g. tar). If your tool overwrites files in %TEMP%, consider using a different tool. The less effect you have on the system, the more accurate your data will be.
Containment Side Effects
While you want to avoid modifying the system, you also want to stop the attack and prevent lateral movement. Be aware of the potential side effects of your containment activities. Execution guardrails can sometimes trigger when you quarantine a device; advanced malware may clear the event log, or delete staged data. The key here is to avoid deleting any evidence while still containing the attack.
Showing Your Cards
Lastly, don’t show your cards to your opponent. If your tool automatically submits samples to VirusTotal, don’t forget that it’s public. Attackers can search by hash to see if their tooling has been compromised or is under investigation.
Procedure for Collecting Data
You probably get it by now – Live Response is important, and it’s important to do it right, but what are the actual steps of getting the data? For Live Response, it’s as simple as double-clicking an executable.
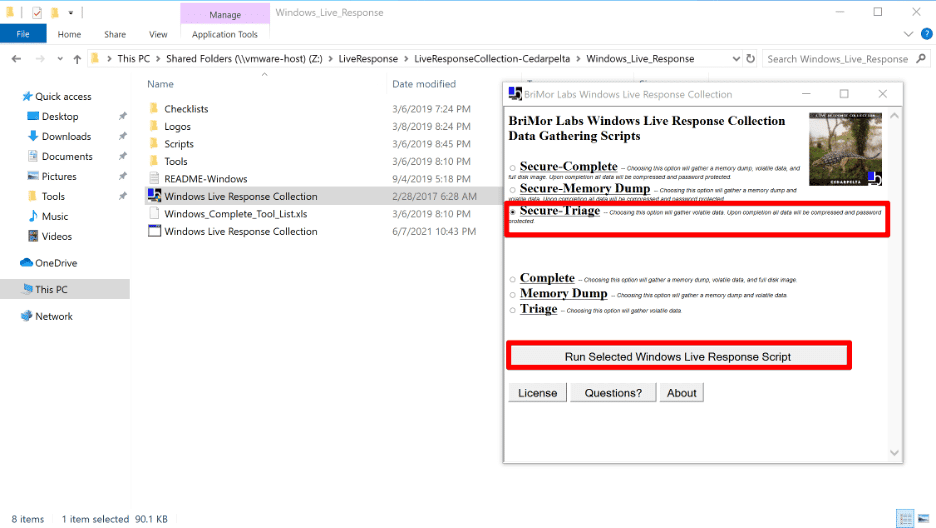
Double Clicking “Windows Live Response Collection” is about as easy as it gets! In this case we ran the “Secure Triage” option to password protect the output.
Analyzing Live Response Data
After collecting the data, it’s important to review it rigorously. To avoid rabbit holes and ensure that you are making progress toward the investigation, you should be able to concisely answer the question, “What am I doing, and what question(s) am I answering”.
The first question to answer is, “What is the system time?” Look at the local time and the current time in GMT/UTC and pick one to use. Praetorian thinks about events in GMT/UTC instead of the system time or local time. Ensuring that all of your timestamps are in the same timezone will help you timeline and understand the order of events. We choose GMT/UTC because a lot of tools already standardize in this timezone, and it’s universal when offices span multiple time zones or observe daylight saving time.
After learning the time, answer a few additional contextual questions:
What OS, version, and build number is this running?
What patches or hotfixes are applied?
What is the system’s current IP address and network state?
Next, do a couple of checks for some low-hanging fruit:
Were any services configured? Do they start at startup?
Is there any suspicious stuff in Live Response’s NetworkInfo/ directory?
After checking the low-hanging fruit, you can begin answering some common questions:
Which users are logged in on the system?
Which processes are currently running on the system?
Which processes have recently run on the system?
Did this system store sensitive information?
Based on the answers to these questions, you should come up with other questions. If you saw Google Chrome running, you might follow up and ask, “What websites did Chrome browse to?” If you saw regedit.exe, you might ask “Were any registry run keys configured?”; you might even ask “Did anyone dump the SAM and SYSTEM hives?”. If you come to a standstill, you can always think about the logical next step that an attacker might take and ask if that happened, or you can turn to the MITRE ATT&CK framework and ensure that all of your bases are covered.
Lastly, you should consider whether the question you are asking is helpful. A good benchmark is asking yourself “will the answer to this question change anything?”. I often find myself asking “who did this?”, but attribution is hard and doesn’t usually change anything. In the end, knowing who or what was behind the attack won’t change any remediation steps, and it won’t change how you go about investigating anything. On the flip side, if you can attribute something to a known group or operator, you might kick off a threat hunt for related IOCs. As you learn and grow, you’ll start to understand what is and is not important to your investigations. After you determine what is and is not important for your investigations, you should develop a LiveResponse investigation playbook.
Drawing Conclusions
At the end of the day, you will need to draw a conclusion. Your conclusion should be based on the evidence that you reviewed and should have some level of confidence. One way to ensure that all statements are based on evidence is to include a “because” statement.
The phrase “I think this device was compromised because Alice logged in over the weekend and Alice doesn’t work weekends” is a lot less confident than “I believe with moderate confidence that this device was compromised because we noticed Windows Event logs consistent with a successful password guessing attack during atypical work hours”. The second statement is more reassuring because it ties the conclusion (device is compromised) to specific evidence (Windows Event Logs) and includes a statement of confidence. In this example, the confidence is implied by the pattern of the events: Seeing a bunch of 4625 events and then a 4624 event is a pretty good indicator of a successful password guessing attack; seeing a lone 4624 event is not a good indicator.
The abstraction of evidence should impact your confidence in your conclusions. If something is abstracted, it can change during an investigation. For example, usernames are not the same as the users themselves, they are an abstraction of the users. Anyone with the credentials to the account can act as the username. The more layers of abstraction, the less confident you can be about your conclusions. Take files for example; file hashes are an abstraction of files, but how likely are two hashes to have a collision? Filenames are also an abstraction of the file itself, how likely is it that the file is masquerading? These two Indicators of Compromise (IOCs) have different levels of abstraction and should therefore, have different levels of confidence.
Lastly, we assess our evidence source. How reliable is it? Historical data may be less reliable than industry agreed indicators and data sources. Calling up a user and asking a question can sometimes be high fidelity, but that depends on the question and how long ago the event in question occurred. “Alice has never heard of the system that indicates she logged on yesterday” and “Alice said she thinks she may have run PsExec sometime last month” have two very different confidence levels.
After assessing your confidence in each answer, put it all together to draw a final conclusion:
- Alice successfully logged on to the server yesterday because there was a 4624 event in the Windows Event Logs.
- I am fairly confident that the 4625 events followed by a 4624 event is indicative of a successful password guessing attack because of my experience.
- I am very confident that the user Alice does not typically log in to this jump server because she told me so over the phone.
- PSExec.exe executed on this system, because Shimcache contained an entry for it.
- I am sort of confident that we do not execute PsExec on this RDP jump server because PsExec has not been executed before on any other systems.
- I am very confident that the PsExec file in question was masquerading because its file hash is associated with a known trojan on VirusTotal.
- Therefore, I am fairly confident that this jump server has been compromised.
This chain of logic allows you to trace the attack, understand what happened, and can easily be followed by others. Additionally, it gives you several additional pieces of work: first, you will want to remediate the attack by changing Alice’s password. Second, you may want to review the host for the presence of persistence mechanisms, and third, you may want to search for lateral movement.
Future Work
Future work on this topic will likely revolve around specific Live Response cases. These may include a Live Response walkthrough for Windows, Mac, and Linux systems, or deep dives into Incident Response topics such as timelining, tracing attack paths, and remediation steps.
Conclusion
The cool part about a Live Response is that it’s super broad in scope. The hard part about a Live Response is that it’s super broad in scope. There’s a ton of evidence to review, and ultimately, it comes down to knowing what is likely and where to look for it. As long as you stick to your plan, stay curious, ask questions, and draw confident conclusions based on evidence, you’ll be improving your ability to analyze compromised endpoints and save the day.
