
Introduction
This blog series discusses OAuth 2.0 from the perspective of a security engineer in both an offensive and defensive role. It describes a basic threat model of the protocol, common attacks in the wild against implementations of the protocol, and how to defend both client and server implementations against these attacks. The goal of this document is to provide security engineers an understanding of how to assess an OAuth 2.0 implementation and to help developers implement this framework securely from both a client and server perspective. Before getting into the weeds, we will explore the OAuth 2.0 framework at a high level and define some terminology.
What is OAuth 2.0?
OAuth 2.0 is an authorization framework that is used to delegate limited access from one service to another. Typically, this involves a user delegating access from their account in one service to an account in a third-party service. The magic of OAuth 2.0 is that it allows this access to be delegated with specific, limited authorization scopes and without ever sharing user credentials between the services.
Imagine the following use case: You are developing a messaging application and you want to allow users to integrate with their Facebook account so that they can automatically add all of their friends when they sign up for the application. A naive solution to this, which modern internet users would be repulsed by, would be requiring the users to enter their Facebook credentials into your application. A modern solution is to use OAuth 2.0 to integrate your users’ Facebook accounts into the messaging application. In this case, users can grant the messaging application access specifically to viewing Facebook contacts without allowing any other Facebook actions to be performed, such as adding new friends.
Now, if the application were malicious or if the application were compromised in the future, users could be sure that the blast radius into their Facebook account would be quite limited. We’ll continue with this example to aid in the terminology definitions to come.
From a user perspective, the flow here for authorizing the application to use your Facebook account would be the following:
- The user is sent to a special URL on a *.facebook.com domain, where they can authenticate if they are not already logged in.
- The user is presented with a consent screen indicating the scope(s) that the application is requesting. In this case, it would be one scope of “read contacts” or something similar.
- The user is redirected back to the messaging application with a special code or token that can be used by the application to view the user’s Facebook contacts.
You will note that sensitive tokens are returned using HTTP redirects in the handshake. One reason for this is that Cross-Origin Resource Sharing (CORS) had not been finalized as a W3C standard at the time that OAuth 2.0 was introduced, making it difficult to share tokens across domains. Many of the defenses and potential attacks on OAuth 2.0 are focused around securing these redirects.
Terminology
- Access Token – A token used to access protected resources. Example: The token that is issued to the messaging application, which can be used to view Facebook contacts of the user.
- Authorization Server – A server that issues Access Tokens and performs authentication. Example: The Facebook server where users are redirected to, where they can authenticate and authorize the messaging application to view their contacts.
- Resource Server – A server that holds protected resources and will provide them if presented with a valid Access Token. This is often the same server as the authorization server. Example: The Facebook server where user contacts are stored.
- Resource Owner – An end user who is granting access to certain privileges (scopes) on the resource server to a client. Example: The Facebook user who wishes to integrate their account into the messaging application, granting access to their Facebook account.
- User-Agent – Browser or mobile application via which the user (resource owner) communicates to the authorization server. Example: An integrated browser window that appears as a result of the resource owner initiating the OAuth 2.0 flow from the third-party application. The User-Agent may also be the first party application (such as the Messenger Facebook App on a mobile device).
- Client – An application that uses the Access Token of a Resource Owner to request protected resources from the Resource Server. This is sometimes the same as the User-Agent, although often the client is a back-end server, referred to as a “confidential client” rather than a “public client”. Example: The messaging application that users are granting Facebook limited access to.
- Client ID – A public identifier for the client, which allows the server to identify the requesting application.
- Client Secret – A secret shared only between the client and the server, which is used to authenticate the client.
- Authorization Code – A temporary code, used in the “Authorization Code” OAuth 2.0 flow, which is generally granted to a User-Agent/Client from the Authorization Server. Then, the Client can exchange the Authorization Code for an Access Token. Often, the Client must present both a Client Secret and an Authorization Code to retrieve an Access Token.
Flow Types
There are various “flavors” of the OAuth 2.0 protocol, often referred to as different OAuth 2.0 “flows”. The most commonly used of these flows are the “Implicit” flow and the “Authorization Code” flow. Often, OAuth 2.0 servers will support both of these OAuth 2.0 flows, and the client will generally use one of the two by default. The flow in use can be identified by the “response_type” HTTP GET parameter sent by the client during the OAuth 2.0 handshake. Specifically, a value of “token” indicates the implicit flow is in use, and a value of “code” indicates the Authorization Code flow is in use.
Implicit Flow
The implicit flow is generally used for public Clients, such as Single Page Applications (SPAs) or mobile applications. In this flow, the Access Token is returned directly from the Authorization Server to the User-Agent. The implicit flow is convenient for easily passing tokens from a mobile or desktop browser to a mobile or desktop application. It should be noted that the implicit flow is essentially deprecated, as it is no longer recommended under any circumstances. The following diagram illustrates the steps of the implicit flow:
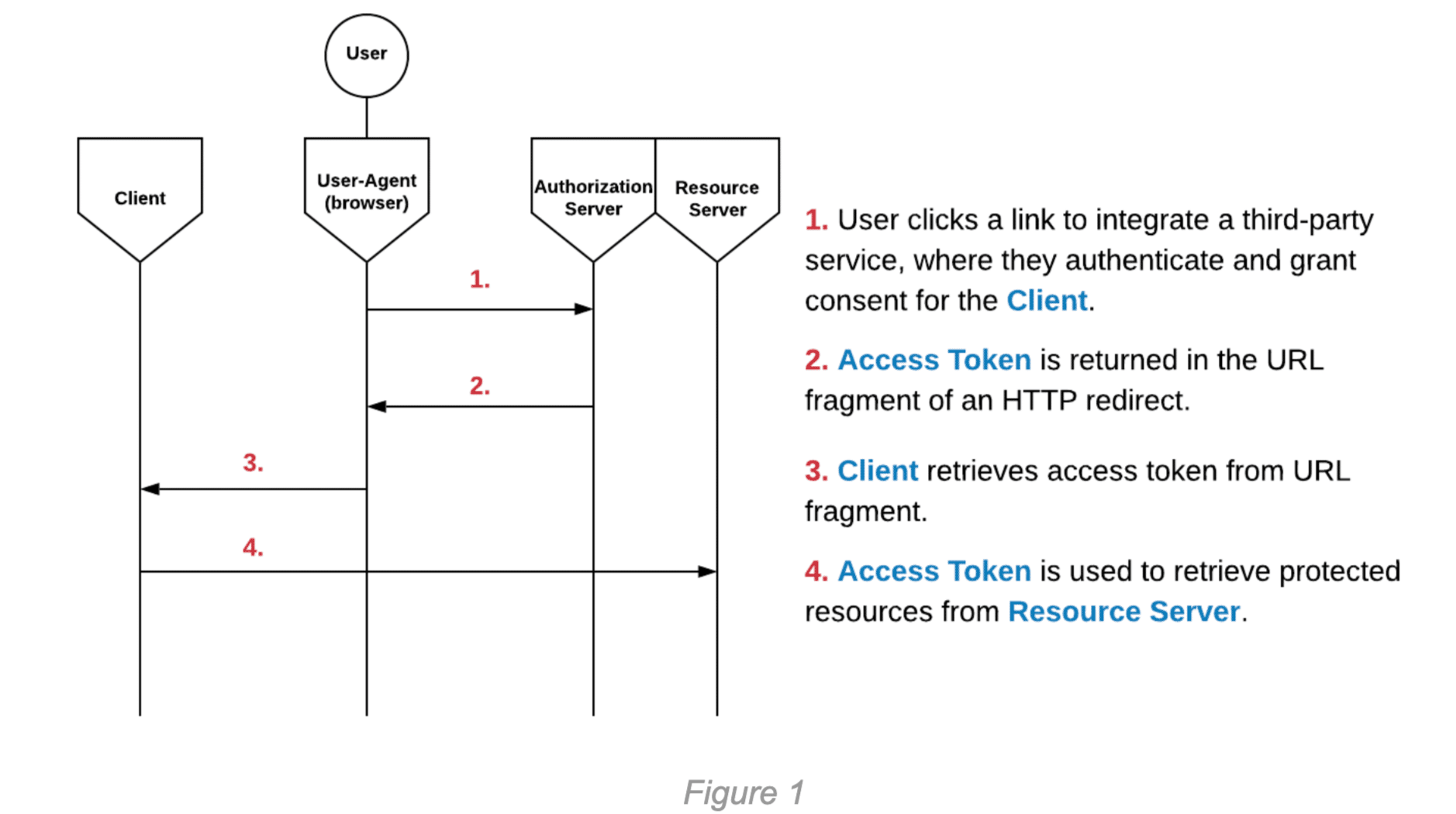
Authorization Code Flow
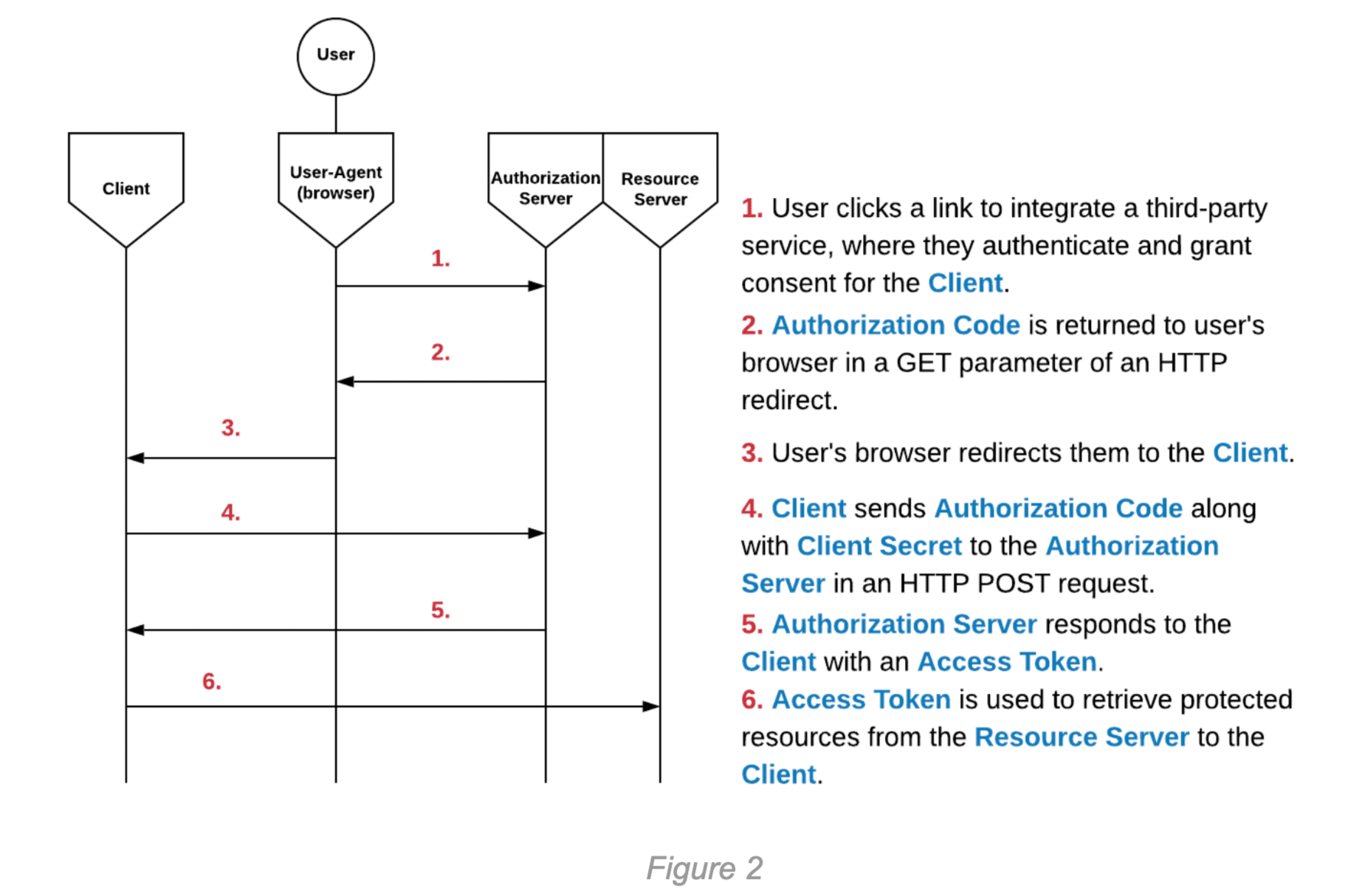
The primary difference in the Authorization Code flow is the addition of an Authorization Code. The Authorization Code is sent to the Authorization Server by the Client, along with the Client Secret, in exchange for an Access Token for the user. With confidential Clients, the Authorization Code allows the Access Token to remain concealed from the User-Agent. The following diagram illustrates the steps of the Authorization Code flow:
Threats: Impact of Compromise
This section will describe the threats faced by OAuth 2.0 implementations and their impact. This section intends to help developers understand why certain OAuth 2.0 best practices are recommended and to help security engineers accurately assess the severity of issues in OAuth 2.0 implementations. This section will focus specifically on the impact of compromise rather than exploitation tactics, as exploitation will be the main point of discussion in our next blog post on OAuth 2.0.
Compromised Access Token
If an Access Token is compromised by a malicious actor, it can be used to request protected resources from the Resource Server with whatever scopes were granted by the user. Consider the difference between a compromised user session token in a Client application and a compromised user Access Token. An example of this would be if a user of a confidential Client application fell victim to a Cross-Site Scripting (XSS) attack or otherwise had their application session token leaked. Since this Client is confidential, their Access Token should remain secure in this scenario. This is because, as previously mentioned, confidential Clients allow the Access Token to remain concealed from the User-Agent. If a user’s session is compromised, but their Access Token is secure, then the extent of the compromise is limited to the functionality of the application.
Imagine a Video-Meet application that integrates with your email client to automatically send your contacts reminders of upcoming meetings they have with you. To perform this action, the application would likely need to request a general permission of “send emails”, so that it can send these emails automatically on your behalf. Now, if a user’s Video-Meet application session is compromised, the worst an attacker could likely do is trigger emails to be sent with content such as “Reminder: You have an upcoming meeting with Victim tomorrow at 2:30!”. This is because the attacker is only able to act within the confines of the Meeting Application’s functionality.
If a user’s Access Token was compromised, they could use this to send any email with arbitrary content on behalf of the victim. As previously noted, in the Authorization Code flow with confidential Clients, the Access Token is never exposed to the end user, which is a clear security benefit.
Compromised Authorization Code
A compromised Authorization Code could be used to integrate the victim’s third-party account with the attacker’s Client account. In practice, this attack would involve an attacker using the Client application normally and beginning the Authorization Code flow up until Step 3 in Figure 2 above. The attacker can then replace their Authorization Code with the victim’s Authorization Code and continue the flow as normal. This will result in the victim’s third-party account being integrated with the attacker’s Client account. Depending on the context and functionality of the Client application, this can have serious implications. It is worth noting, though, that in confidential Clients, this integration of the victim’s account is generally significantly less severe than an entire compromise of their Access Token, because the scope of the attack may be limited by the functionality of the Client application.
Compromised Client Secret
If a Client Secret were compromised, the attacker could impersonate the Client. This would allow the attacker to directly exchange Authorization Codes for Access Tokens, potentially including old Authorization Codes that could be replayed. With this in mind, obtaining a Client Secret significantly increases the impact of a compromised Authorization Code (in fact, it equates the risk of an Authorization Code compromise to an Access Token compromise). Additionally, a compromised Client Secret may allow an attacker to create a malicious “phishing” Client application to lure users into integrating with. This malicious Client could provide the legitimate Client Secret and Client ID, making it essentially indistinguishable from the legitimate client to the Authorization Server. It would be difficult for the Authorization Server to then identify (and properly revoke) the Client Secret because it was also in use by the legitimate Client application.
OAuth 2.0 Implementation Best Practices
One of the reasons implementing OAuth 2.0 securely is so difficult is that best practice recommendations have changed multiple times since the RFC for the framework was published. A draft of the current security best practices was published by the IETF in April of 2020. Below, we will explore the current best practices for a client and a server. This section will ignore vulnerabilities introduced by not following the OAuth 2.0 protocol, and it will instead focus on best practices for correct implementations. Such vulnerabilities and their exploitations will be covered in Part 2 of this blog series.
Use the Authorization Code Flow
First and foremost, the Authorization Code flow is always recommended to be used rather than the implicit flow, regardless of whether or not the Client is public or confidential. Previously, the Authorization Code flow could not be implemented with public Clients because it would expose the Client Secret. The Authorization Code flow can now be implemented with public Clients by using an OAuth 2.0 extension called PKCE (pronounced “pixie”), which will be described next. The Authorization Code flow offers the following clear benefits over its implicit flow counterpart:
- Access Token is never placed in a URL
- Access Token can be concealed from User-Agent
- Confidential Clients identify themselves with a Client Secret
Use the “Proof Key for Code Exchange” (PKCE) Extension
PKCE is an extension of the OAuth 2.0 framework that adds additional security and allows public Clients to perform the Authorization Code flow. PKCE has its own RFC, published in September 2015. Before we discuss what PKCE is and how it works, let’s examine what it provides:
- Allows public Clients to use the Authorization Code flow rather than the implicit flow, even though they cannot secure a Client Secret
- Entirely mitigates the impact of a compromised Authorization Code by a malicious actor
At a high level, PKCE works in the following way:
- Before initiating the OAuth 2.0 flow, the Client generates a sufficiently random value as well as a SHA-256 hash of this value. The random value is called a “code verifier” and the hash is called a “code challenge”. This value should never be reused between different flows, and essentially is to be treated as a nonce.
- In the Authorization Code request (during Step 1 in Figure 2), the Client includes the “code challenge”, which the Authorization Server must store and associate with whatever Authorization Code is returned for the user.
- In the request to exchange the Authorization Code for an Access Token, the Client must also include the “code verifier”. The Authorization Server must now compute the SHA-256 hash of this value and check that it is equal to the “code challenge”. If it is equal, the Access Token is returned, otherwise, the flow fails.
Previously, if a public Client were to implement the Authorization Code flow, their Client Secret would have to be public. This would mean that Authorization Codes were just as valuable as Access Tokens (because any attacker could use the Client Secret to exchange them), which would eliminate the benefits of using the Authorization Code flow over the implicit flow.
Now, imagine if an attacker were to compromise an Authorization Code during the OAuth 2.0 flow of a victim. The attacker could not do anything with it unless they also compromised the “code verifier”, which is never returned in any HTTP responses or used in any redirect URLs. In practical terms, this implies that the Client/User-Agent itself must be compromised as an attacker would need to read the internal memory state to have access to the “code verifier” that was used in the challenge.
Unfortunately, much documentation online states or implies that PKCE is specifically for public Clients. With this in mind, it is no wonder that PKCE is underused and undervalued in confidential Client applications. As stated in the previously mentioned IETF draft, PKCE is recommended for all Clients, both public and confidential. You might be asking yourself why PKCE would be relevant in confidential Clients, where a securely stored Client Secret must be presented to retrieve an Access Token. After all, the entire point of PKCE is to allow public Clients to perform the Authorization Code flow without a Client Secret. The answer to this is that PKCE and the Client Secret solve different, but similar, problems:
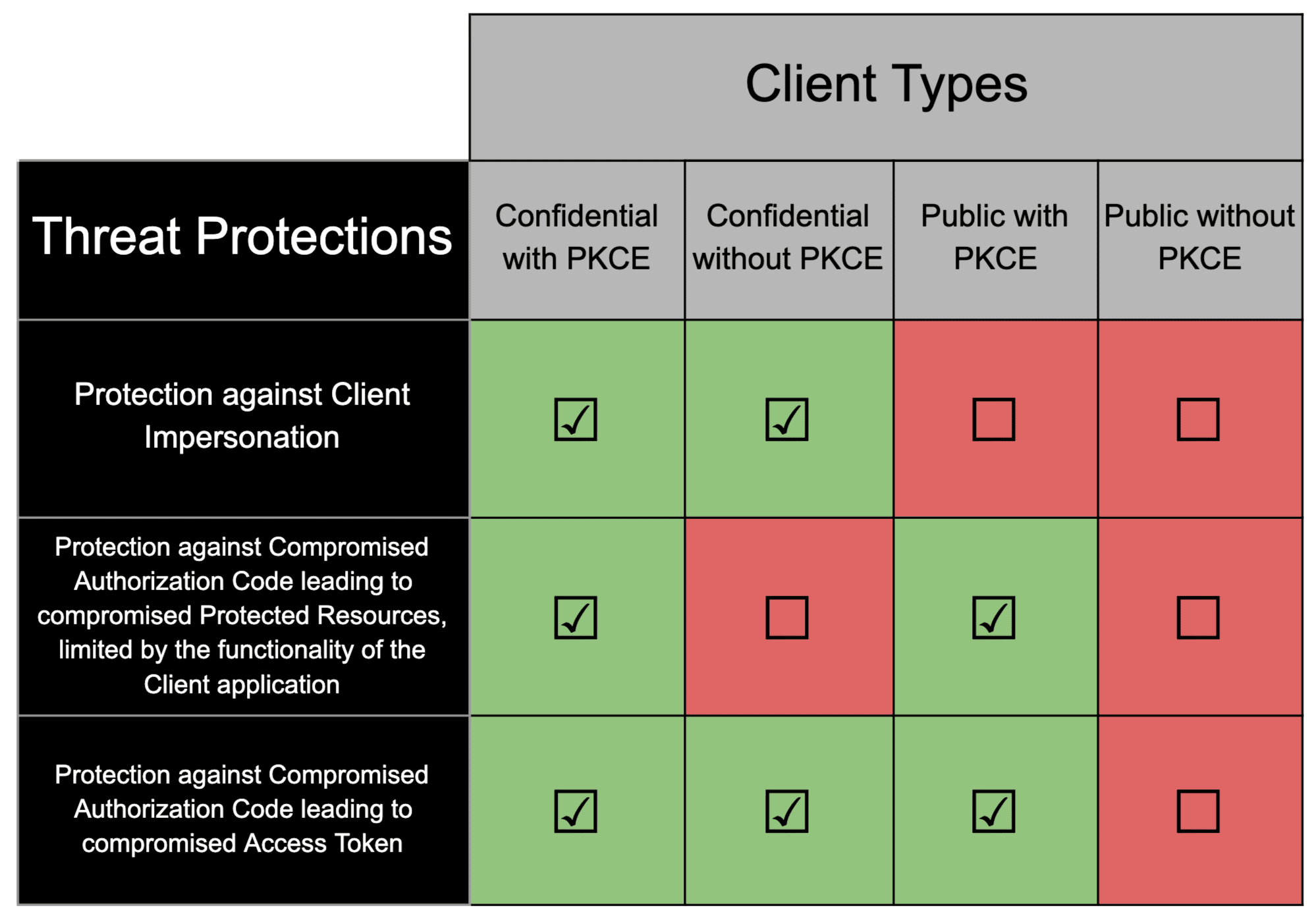
- The Client Secret prevents an attacker from freely exchanging an Authorization Code for an Access Token. As previously mentioned, in confidential Clients this can still allow compromised Authorization Codes to lead to compromise of the victim’s Protected Resources, with the limitation of the functionality of the Client application.
- PKCE ensures that the Client that began the OAuth 2.0 flow is the same Client that is completing the OAuth 2.0 flow. Thus, if an Authorization Code is compromised, there is nothing that can be accomplished with it if PKCE is properly required to be used.
The following table demonstrates various protections achieved by using PKCE with public and confidential Clients.
Require the State Parameter
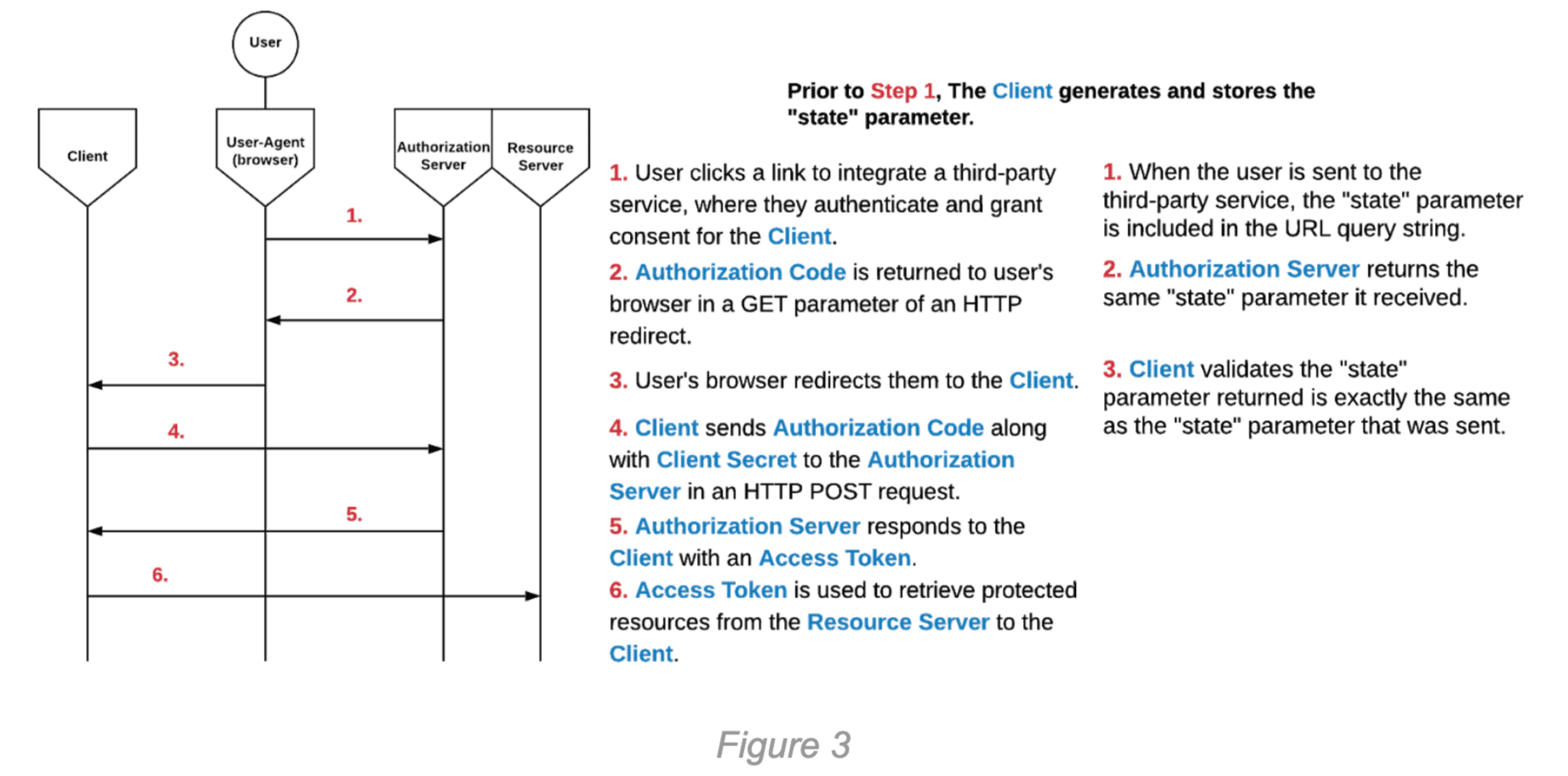
The “state” parameter, recommended by the OAuth 2.0 RFC in Section 4.1.1, binds authorization requests to a specific User-Agent. This prevents Cross-Site Request Forgery (CSRF) attacks which would allow an attacker to force a victim to integrate the attacker’s third-party account with the victim’s Client account. The attack works by enticing a victim user to browse to a Client URL that contains the Access Token or Authorization Code of the attacker, integrating the attacker’s account. In many cases, this CSRF attack can be benign, but depending on the context, the risk can drastically increase. Imagine a scenario where a user has integrated their PayPal account with a Client, which they use to withdraw money from the Client into their PayPal account. If a CSRF attack was possible here, the attacker could integrate their own PayPal account with the victim’s Client account. The implementation of the “state” parameter is very simple in its nature; it works in the following way:
- The Client generates a sufficiently large random value and stores it in the User-Agent (this can be stored in browser Cookies, for example).
- During the OAuth 2.0 flow, the Client includes an additional “state” parameter in its request to the Authorization Server.
- When the Authorization Server responds to the Client with an Access Token or an Authorization Code, it includes the same “state” parameter that it was given.
- The Client must validate that the “state” parameter that was sent equals the “state” parameter that is stored locally in the User-Agent. If the “state” parameters do not match, then the Client should exit the flow.
This process can be seen in the diagram below. The diagram shows the same flow from Figure 2, with the steps relevant to the “state” parameter shown in the right column. These steps occur at the same time as the steps in the left column.
The above explains the security purpose of the “state” parameter, but it can also be used to store information about the Client’s state, such as where the user should be redirected back to after the OAuth 2.0 flow completes. If the “state” parameter is used to store this additional data, it must either be cryptographically signed, or it must be concatenated with a sufficient amount of random data that can be validated in the manner described above.
Implementation of the “state” parameter is similar to PKCE in that they both ensure the party beginning the flow is the same party that is completing the flow. PKCE verifies that the Client completing an OAuth 2.0 flow is the same Client that began the OAuth 2.0 flow, and the “state” parameter verifies that the Client user completing an OAuth 2.0 flow is the same user that began the OAuth 2.0 flow.
Conclusion
OAuth 2.0 has grown and changed since its inception, and its best practices have grown with it. Developers and security engineers should be wary that much documentation online is still recommending practices that are outdated. In the next blog, we will discuss common OAuth 2.0 exploits and vulnerabilities seen in the wild in applications. Now that we’ve covered the basics of the framework and its defenses, the next blog can get into specific attacks on the protocol.
