In previous blog posts we’ve talked about getting nerd sniped. Today we’re going to talk about a kind of nerd sniping that any offensive security tool creator is familiar with; when your tool gets signatured. This normally kicks off a frustrating spiral of back and forth changes between the tool author and security vendors until the tool author runs out of resources to keep responding to changes. Like many parts of the security space, LLMs have changed how this story might end.
The Classic Offensive Security Tooling Lifecycle
There’s a lifecycle to most offensive security tooling. First you encounter a problem that’s common or problematic enough that you want to automate it, so you write a tool. Then you use that tool privately until you decide the time has arrived to open source it. This is a cool moment, you get to share your techniques with the community and if you’re really lucky, maybe the fundamental problem your tool exposes is fixed. Much more likely, once it’s open sourced it eventually gets signatured to the point that you can’t even download it anymore. The name of your tool joins the ranks of tools like mimikatz such that it might as well become the EICAR string and suddenly goes from running on everything to triggering alerts everywhere. This is just the nature of publishing offensive security tooling.
It’s also really annoying.
A Case Study in Tool Signatures
Two years ago we published goffloader. It’s a fairly vanilla BOF loader implementation in pure Go. It still doesn’t do too badly if you upload it to VirusTotal. But it doesn’t show as clean. This makes sense – it’s doing some pretty suspicious stuff, but what needs to be detected is the actual behavior, not just a check to see if Goffloader was used. For example, Elastic identifies the goffloader test binary as Multi.Trojan.Goffloader. It’s neat to be explicitly identified, but you can see in the Elastic Yara Sig that it’s simply keying on one of the build import strings praetorian-inc/goffloader/src/memory.ReadUIntFromPtr.
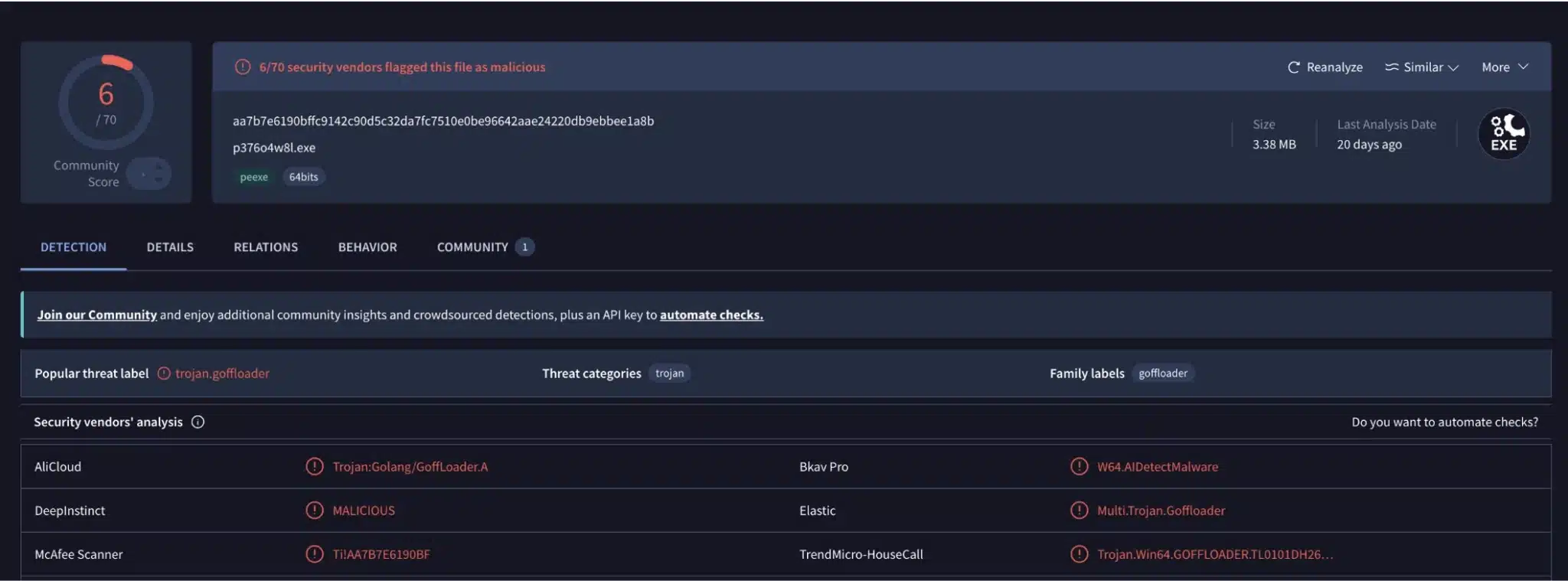
No big deal, we can try building the binary with flags like -trimpath -ldflags “-s -w” to not include the debug information with this binary. You can see the results here.
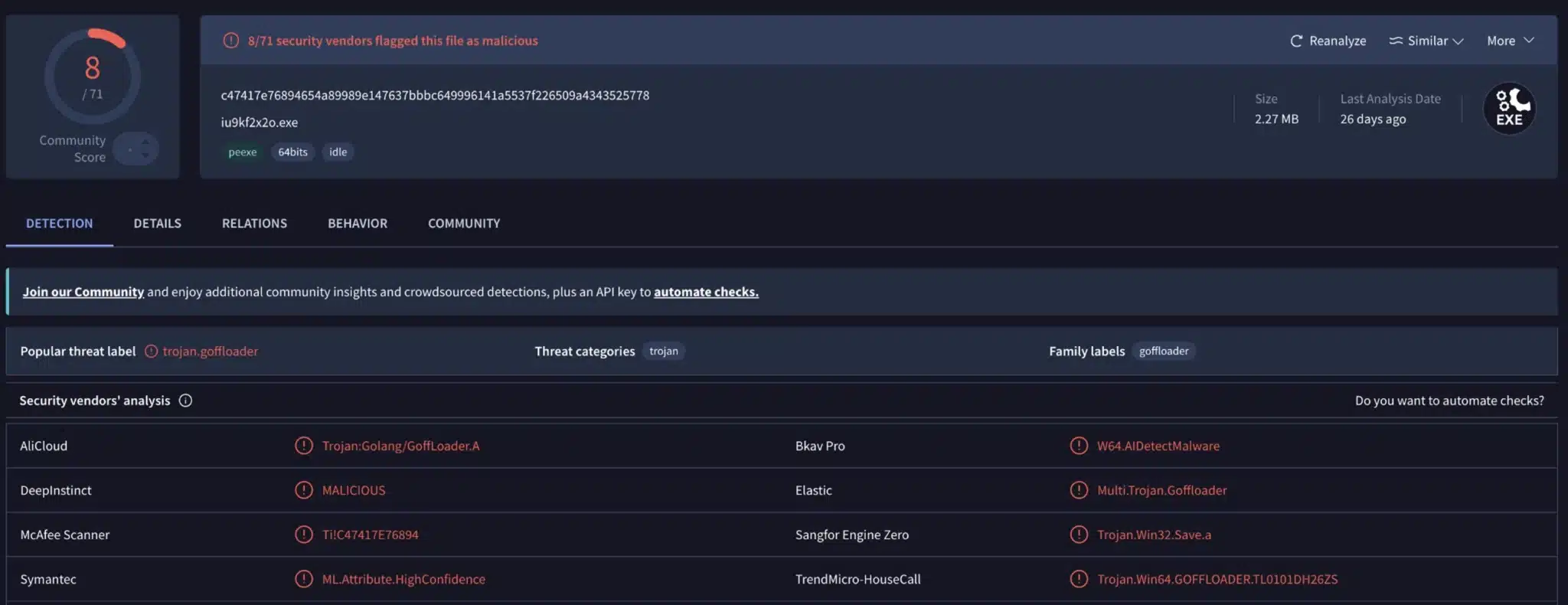
Sadly enough, this actually triggers MORE detections while not actually removing the package names. Go’s compiler keeps the symbols for the purposes of reflection so Elastic can still identify the string (there’s a reason they picked a package name for the signature). Additionally, stripping the debug information actually causes a few more engines to detect the binary as suspicious since the structure is noticeably different from a vanilla build.
Conventional wisdom is that you should use other tool chains like garble or gobfuscate but these tools ALSO suffer from public usage and will trigger detections. For example you can see that garble now has our binary detected by Crowdstrike Falcon. There’s also significantly more detections. The act of trying to avoid detection has actually made our binary more suspicious looking.
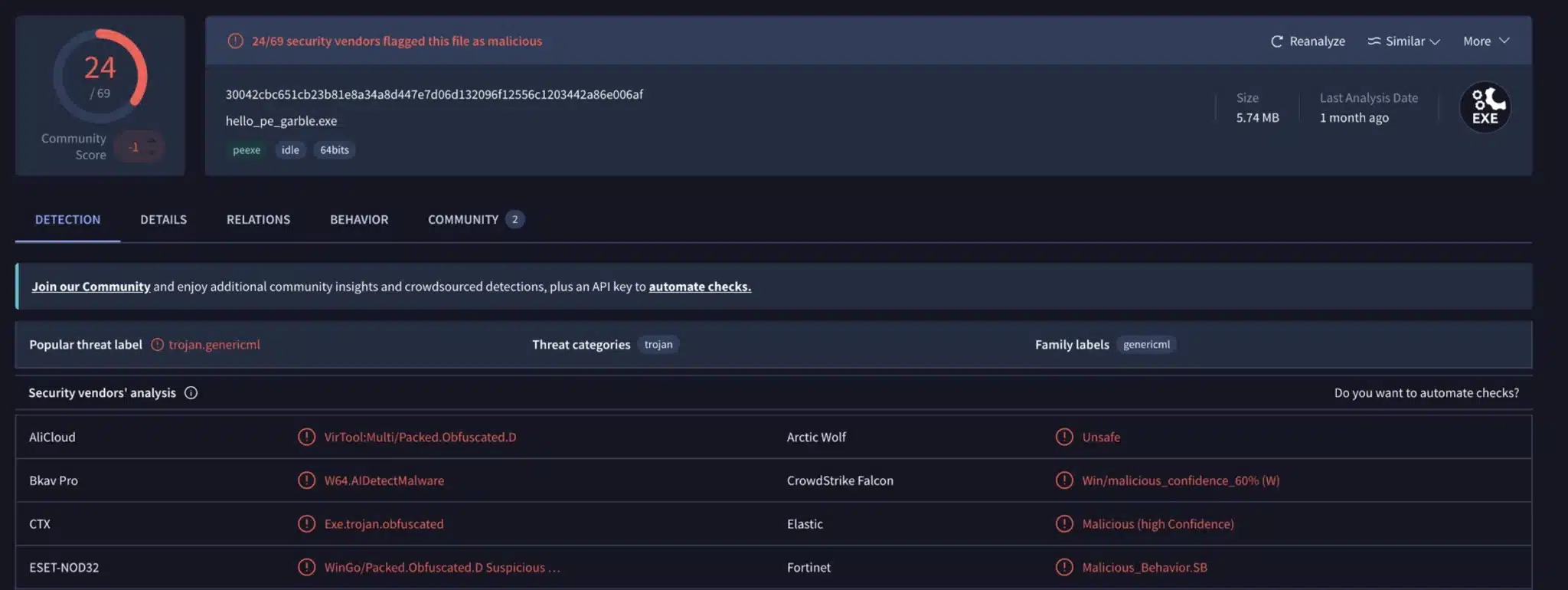
24 detections is hardly a better outcome
So What Next?
Normally this is the point when we start changing strings and hoping for the best. These days you can be more educated about what strings to change by using tools like defender2yara or avred to use existing EDR as an oracle for what parts of our binary are “problematic”. Regardless of whether or not you’re tool assisted or not, this can be a pain in the butt, especially if the signature or metrics used to detect your program are robust.
Where things get especially annoying is with some of the machine learning guided detections. Maybe the entropy in your binary is off because you wanted to use compression so we need to pad the binary out with strings. Maybe we need to change our imports because the current set is too minimal (or too dangerous looking) to be safe software. Maybe the file needs some kind of spoofed Authenticode signature.
Ultimately this is the imposed cost from these defensive signatures. They’re meant to be time barriers versus any serious prevention. It normally means that if we want a tool to remain active we need to spend time hardening our binaries against static analysis (and dynamic analysis as well, but that’s for another blog post).
Agentic Adversarial Oracles
What if we could reduce or minimize that time cost? These days you can do an awful lot with a Claude skill. What we’ve found is that making sure your LLM’s “done” criteria is crucial for ensuring you aren’t fed hallucinations or garbage output. Luckily for us, we have a pretty basic check to use – the VirusTotal API. It doesn’t matter how much an LLM decides to pat itself on the back for a clever solution it spits out if there’s a reliable signal for whether or not it worked. This is the basis for a lot of the test driven development (TDD) discussions with creating skills. Even with solid testing you still need to make sure your success conditions are very well described. For example, we observed a few sneaky attempts where the LLM would just remove all our implant behavior entirely to try to get a clean signature.
Essentially we can take a frontier model like Claude and then use VirusTotal as our “it worked / it didn’t” oracle to help guide decisions. We’ve TKTK generated a Claude skill that can do this TKTK built around reducing detections in golang tooling. Simply create a free account with VirusTotal, generate an API key, write it to a file on disk and then let this skill loose with your binary.
VirusTotal and Operational Security
As a brief aside, some readers are probably wondering about the opsec problems of submitting samples to VirusTotal. Isn’t submitting samples terrible opsec? Sure, in some ways it certainly is, anything submitted to VirusTotal immediately goes into the data collection of every major security vendor. When using their API as any sort of oracle it’s important to make sure that you’re not including any samples with infrastructure links or indications about your target organization. Use placeholder values for your tests.
There is an entire class of tooling where the TTP itself would be the signature. For example certain COM hijacks are going to be explicitly tied to a specific GUID, or perhaps your payload is relying on an embedded signed driver to provide an arbitrary read/write primitive at the kernel layer. In these cases no amount of static obfuscation can protect your binary and we would not recommend this approach. There are absolutely ways to design a skill to protect against behavioral detections, but you’ll need a different oracle than VirusTotal for that case. Anyways, with that covered, back to the actual skill.
What the Skill Actually Does
The loop is simpler than the word “agentic” suggests:
1. Upload to VirusTotal. The skill submits the binary and waits for the engines to finish scanning. We pull the per-engine results back as a flat record.
2. Triage by detection type. Not every hit is the same problem. A YARA-style verdict (Trojan/Win.Sliver.R774471, Multi.Trojan.Goffloader) is fundamentally different from ML.Attribute.HighConfidence or Wacatac.B!ml. The former has fixed bytes the engine is grepping for while the latter is a statistical classifier we have to nudge across a decision boundary. We label each hit so we know what we’re actually chasing as there’s no point trying to rename our way to beating a classifier which doesn’t care about strings.
3. Hunt the trigger. For YARA-style hits, we build a labeled corpus, usually batches of 20-40 binaries from the same source tree, and look at which strings, section names, or imports correlate with detection. This requires using token frequency tables, lift ratios, and scrutinizing the unglamorous statistical differences between files. In general we’re looking for any factors that could explain why our flagged samples were detected versus the ones that were not. Building this hypothesis requires considering a large amount of factors and is exactly the kind of attention that models can outsource for us. An LLM can stare at “this token appears in 91% of detected samples and 7% of clean samples” across thousands of rows and dozens of properties without losing focus or guessing.
4. Modify and rebuild. We rename the offending strings, drop suspicious imports, swap signing identities, restructure sections, or do whatever else the analysis points at. Critically, we make each change as a single-variable hypothesis with a control batch (n ≥ 10) built and uploaded in the same window. We are not rewriting blindly with multiple changes and hoping the next batch lands somewhere better.
5. Re-upload and measure. The free account can handle 4 API calls per minute, so this process needs to be explicitly rate limited. After a few minutes we can observe the new detection rate for our changes and validate if our hypothesis was correct or not. If it wasn’t, then we loop back to step 2 with the new state.
The “done” condition is whatever clean rate the operator is willing to ship with. We’ve generally found that aiming for a 75%+ clean detection rate on VT is a reasonable target. In practice with an agentic harness like Claude, you can just say /goal Use the reduce-edr-detections skill to get our detections under 25% for samples and get the job done.
This skill is helpful, but it’s hardly perfect. Sometimes you need to experiment with other ways to shape a binary that aren’t just entropy based. Even in these cases, the skill is helpful for confirming theories. For example, one of the first places we used this loop seriously was to develop a feature we ended up calling ghost profiles.
False Flagging your Applications with Automation
Ghost profiles came from the observation that ML detections were over-indexing on the contents of the gopclntab. For those less familiar with Go internals, this contains information like a table of function name strings that Go embeds for runtime reflection and stack tracing. A vanilla `hello world` Go binary, compiled with default flags, sits at around 2.5 MB and produces a gopclntab of about a hundred kilobytes. Almost every byte of that table is structural Go-runtime symbols (runtime.mallocgc, internal/poll.(*FD).Read, and so on). Now compile something real like terraform or consul and the same table balloons to multiple megabytes, full of recognizable project-specific paths like github.com/hashicorp/consul/agent/grpc-internal/resolver.ServerResolverBuilder. ML classifiers seem to weight gopclntab content fairly heavily, and the “small minimal binary with mostly runtime symbols” pattern looks indistinguishable to them from a stripped, deliberately-minified malware sample.
The naive fix is to make your binary’s gopclntab look like the gopclntab of a real, large, signed Go project. So we built a small harness that walks the symbol table of any compiled Go binary (go tool objdump gives us TEXT entries for free), filters out the stdlib, and produces a JSON file we can later splice into our build by renaming files in the source code and adding some function stubs so that the build output output matches the ghost target’s gopclntab. We collected profiles from a handful of other open-source infrastructure projects, then started using the skill to figure out which ones actually worked.
For each candidate profile, we built batches of binaries with the same payload but different ghost-profile-derived symbol tables, uploaded everything to VT in a single window, and read off the per-profile detection rate. The skill makes this manageable because the iteration cycle is short. You can also just set and forget it to go nuts with a variety of options overnight, then wake up the next day to see which profiles have the best results. We’ll be releasing the tooling for this in an upcoming open source release.
A few results that surprised us:
Bigger profiles consistently beat smaller ones, and the gap was larger than we expected. Moving from a moderate-sized profile to a substantially larger one cut Microsoft Wacatac ML detection by several multiples on the same payload. The “useful enough to disguise a Go runtime” threshold sits well above what most off-the-shelf open-source projects produce, which turned suitable-candidate hunting into a research task in its own right.
Building larger candidates from source didn’t always help. Hoping to brute-force the problem, we built profiles from kubectl, kube-apiserver, and a handful of other Cloud Native Computing Foundation heavyweights. The symbol tables came back smaller than we’d guessed. Kubernetes is broad horizontally, but most of its packages are thin and dependency-driven. The projects that produced the densest symbol tables were the ones with heavy plugin or backend-implementation patterns, where a single core type spawns dozens of method receivers per backend. Volume of code matters less than volume of distinct typed methods.
Stripping the names entirely was the worst option. Just to confirm the direction, we also ran a small batch with -ldflags=”-s -w”, the same conventional binary-shrinking advice that lit up CrowdStrike on the goffloader experiment up top. It produced the same result here: CrowdStrike and Symantec hit immediately. ML treats the absence of expected debug data as suspicious in its own right.
Like a lot of stealth-related TTPs, you’re better off blending in than trying to kill the signal entirely. The absence of a signal is often just as suspicious to analysis, if not more. That’s why we want to give the ML classifier, or analyst, a believable answer to “what is this binary?”.
Once we had a working ghost-profile pipeline producing reliably clean binaries, the remaining detections started looking less like “your build is suspicious” and more like specific YARA rules with specific triggers. Which brings us to the next example.
Killing the AhnLab Sliver Rule
Last month one of our build pipelines to obfuscate Sliver started getting hit at 100% by AhnLab with Trojan/Win.Sliver.R774471. Not 100% in a noisy way either, every single binary that we’d faked a digital signature for was detected with that exact rule. The unsigned variants of the same payload were clean against AhnLab but lit up CrowdStrike, Elastic, and Symantec on the ML side. We were stuck choosing between two flavors of detection and that’s not really a choice we wanted to make.
While AhnLab isn’t something that we see installed on customer machines, we’ve found that there is a difference between how binaries are treated when there are ANY detections from VirusTotal versus zero. Most likely this is part of a machine learning metric which tags 0 as clean, 1 to N as suspicious, and N+ as bad. In one case, we had a binary examined in a customer network and our point of contact shared their triage report in which the SOC clearly threw the binary into a multi-EDR scanning product. Because our binary had 0 detections on it, the detection product labeled our Sliver binary goodware and the IR team moved on. It’s also a bit of future proofing. Just because a binary is clean against Microsoft or CrowdStrike one day doesn’t mean it will be the next. ML detections from other vendors are bellweathers of potential detections from what IS running on your target hosts.
With that in mind we pointed the skill at a labeled corpus of around 90 builds, roughly half signed and half not, spread across a couple of ghost profiles to control for string related signals. Token correlation surfaced exactly four byte-identical strings present in every signed binary: a fixed company name in the certificate subject, a fixed ” TLS CA” suffix on the issuer, and the two hardcoded osslsigncode flags (-n “Application Service” and -i “https://support.microsoft.com”) that had been pinned in our signing code for months. None of these are technically suspicious on their own, they appear in legitimate signed software all the time, but the combination was apparently distinctive enough for AhnLab to write a rule against it.
The fix was a quick source change. We converted each of those four hardcoded strings into a per-build random pick from a pool of plausible alternatives, rebuilt, and re-tested at n=20.
AhnLab dropped from 100% to 0%. CrowdStrike, Elastic, and Symantec all stayed at 0%. The result reproduced the following day at the same clean rate, confirming the change was real and not just classifier retraining drifting our way for an afternoon.
The wall-clock time for the fix was an afternoon, but it was a single prompt in Claude that resolved this. Normally it would have taken a great deal more time to run this down.
Other Observations and Takeaways
A handful of observations from actually using this on production tooling, in case any of it spares somebody else the same time:
Same-batch controls matter more than you’d think. Some VT scanners update or change behavior on a daily cadence. If you measure n=10 before a change and n=10 after, and the two runs are separated by even a few hours, half your apparent delta is just model drift. In practice this means you can’t use your detection rates from running this skill a few days ago. Always use fresh detection data to guide the skill. The only way to isolate the actual signal from your modification is to build the control and the variant in parallel, upload them in the same window, and read them off the same model.
Don’t fight the toolchain. If you’re shipping a Go binary, it should look like a Go binary. We’ve tried patching the linker version to look like MSVC, adding a fake Rich header, and stripping the .symtab entirely. Every single effort made detection worse, because 40 features still say “Go” and 1-2 now say “MSVC” and the inconsistency itself becomes the signal. Move features toward the natural toolchain baseline, not away from it.
Bulk string dilution does more work than you’d expect. When we swapped our ghost profile from a moderate-sized project to a substantially larger one, Microsoft Wacatac dropped from around 95% to around 20% on otherwise-identical binaries. The runtime fingerprint hadn’t changed at all, there were just multiples more legitimate-looking function names in the gopclntab to dilute the suspicious ones. Coherence matters too: pick a single large real project rather than trying to inflate the bulk artificially. While we have the numbers explicitly for Microsoft here, this almost certainly applies to other detection engines as well.
VT is not ground truth, despite the temptation to treat it that way. Many EDRs have local detections and cloud detections. For example, Microsoft’s cloud ML is substantially more aggressive than the local Defender engine. A binary that’s 100% Wacatac on VirusTotal can be clean against MpCmdRun.exe on an actual Windows endpoint. VT is a useful oracle for measuring signature pressure, but optimizing against it past the point of diminishing returns means spending time on a benchmark that isn’t your actual threat model. It is possible to get signatures reliably down to 0% for weeks against the Microsoft classifier, but in practice we haven’t had problems running binaries on MDE machines when we get the detection rate sufficiently low.
What’s Next
We’ve been running this loop pretty hard against a new loader we wrote, with a fairly specific goal: take an existing, signatured Go tool like Sliver or Chisel and produce a binary that’s operationally safe again without modifying a single line of the tool’s source. The loader compiles the original tool to WebAssembly, wraps it in a runtime that proxies syscalls and Win32 APIs back to the host, and ships the WASM payload encrypted inside an outer Go binary disguised as a real piece of infrastructure software. The skill above is what we use to keep that outer disguise effective against detectors that retrain faster than any single human team can manually adapt. We’ll be publishing another blog post about this very soon, so watch our blog for more information.
