What’s the first thing you think of when you hear about AI attacks and vulnerabilities?
If you’re like most people, your mind probably jumps to Large Language Model (LLM) vulnerabilities—system prompt disclosures, jailbreaks, or prompt injections that trick chatbots into revealing sensitive information or behaving in unintended ways. These risks have dominated headlines and security discussions, and for good reason: they’re novel, they’re interesting, and they affect some of the most visible AI deployments today.
But here’s what keeps us up at night: while security teams worry about chatbots leaking secrets, attackers could be dropping payloads targeting the production infrastructure itself.
The attack surface for AI systems extends far beyond conversational interfaces. The platforms that host, train, and deploy machine learning models—the infrastructure that powers everything from fraud detection to recommendation engines—present an entirely different class of risks. These are the platforms that enable businesses to build, test, and deploy ML models at scale, often with self-service capabilities that prioritize ease of use over security isolation.
During a recent red team engagement, our team encountered one of these platforms in the wild, and what we discovered illustrates why the security community needs to expand its thinking about AI risk.
The Setup: How Modern AI-Powered MLOps Platforms Create Attack Surface
Modern MLOps providers are looking to solve the problem of how they can streamline the adoption of ML across business units. Some platforms are opting to provide developers with managed infrastructure to train and deploy models quickly. The appeal is obvious—developers can go from idea to production in hours rather than weeks.
From a business perspective, this is exactly what you want: low friction, rapid onboarding, and quick time-to-value. Users can self-register, receive their own isolated environment in a cloud provider, and begin experimenting immediately. Once a model is built and trained, the platform handles deployment, exposing it through an authenticated API endpoint that can be called from anywhere.
It’s elegant. It’s modern. And as we discovered, it’s also a potential gateway into your internal network.
The Attack: Turning AI Infrastructure Against Itself — Remote Code Execution via Model Deployment
Our objective was simple: What could an adversary do with nothing more than a self-registered trial account?
The answer turned out to be: Quite a lot.
The attack chain we developed exploited a fundamental characteristic of ML platforms—they need to execute code. Machine learning models aren’t just static files; they’re executable artifacts that process inputs and generate outputs. In this case, we leveraged that execution capability to deploy what appeared to be a legitimate ML model but was actually a malicious payload.
Here’s how it worked:
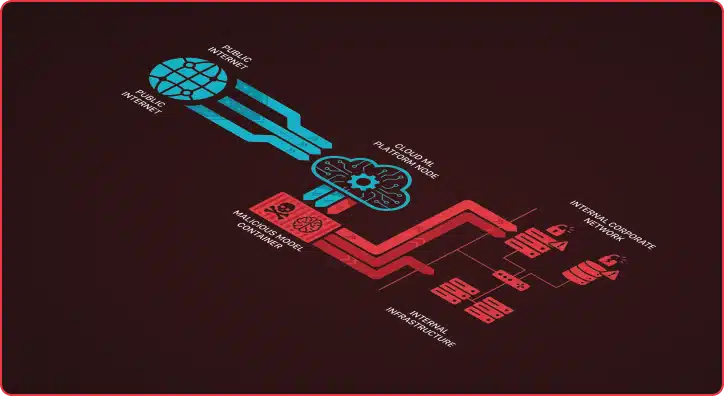
The platform allowed us to create and deploy a model that accepted custom parameters as part of its API requests. We designed our model to accept a specific parameter: a URL pointing to a malicious code snippet. When the model received an API request containing this URL, it would retrieve the content from that snippet and execute the code within the container where the model was deployed.
From the platform’s perspective, this appeared to be normal model behavior—processing an input and generating an output. But in reality, we had just created a remote code execution capability in the provider’s infrastructure, all through a self-registered trial account.
We used this capability to deploy command-and-control (C2) infrastructure directly onto the platform’s underlying cloud environment. A “random person” on the internet—with no legitimate business relationship, no pre-existing access, and no stolen credentials—now had a foothold in the provider’s infrastructure.
The Real Problem: Cybersecurity Network Access and Trust Boundary Failures
Deploying malicious code is concerning, but what made this situation critical was what came next: network access.
The containers hosting deployed models weren’t entirely isolated from the provider’s internal resources. Our C2 beacon could reach internal services, databases, and infrastructure that should have been completely inaccessible to external users. The trust boundary that should have existed between “customer/client infrastructure” and “internal corporate resources” was either poorly implemented or non-existent.
This is where a security issue becomes a business-critical risk. An attacker who gains this level of access could:
- Exfiltrate sensitive data from internal databases, APIs, and services that trusted the ML platform’s network space
- Establish command-and-control infrastructure that survives account deletion (by deploying additional backdoors to the underlying cloud infrastructure before the account is terminated)
- Use the compromised container as a trusted insider to pivot deeper into the network and discover additional high-value targets
All of this from a free trial account that took minutes to create.
Why This Matters: The Convergence of AI Security and Cloud Security
This type of vulnerability sits at the intersection of multiple security domains: application security, cloud infrastructure security, ML operations (MLOps), and red teaming. It’s a blind spot that emerges when organizations focus heavily on one type of risk (like LLM prompt injection) while underestimating the security implications of the platforms themselves.
Several factors make these risks particularly challenging:
First, the self-service model prioritizes user experience over security isolation. Organizations want to reduce barriers to adoption, which often means automating environment provisioning and minimizing security friction. This is a business requirement, but it creates opportunities for abuse if trust boundaries aren’t carefully designed.
Second, ML workloads require significant compute and execution capabilities. Unlike traditional web applications that might serve static content or make database queries, ML platforms must execute arbitrary code as part of their core functionality. This makes them inherently more difficult to sandbox and isolate.
Third, the rapid evolution of ML tooling means security practices often lag behind deployment. Organizations are under pressure to deliver ML capabilities quickly, and security reviews may not fully account for the unique risks these platforms present.
Secure AI: What Organizations Should Do
If your organization operates a customer-facing ML platform, especially those with self-service capabilities, consider these security principles:
Assume all users are adversaries. Design your isolation boundaries with the assumption that some percentage of accounts will attempt malicious actions. This isn’t about being paranoid—it’s about realistic threat modeling.
Implement strict network segmentation. Customer environments should have no connectivity to internal resources by default. Any necessary communication should flow through well-defined, heavily monitored interfaces with explicit allowlisting of permitted connections.
Monitor model behavior and resource access. Unusual API patterns, unexpected network connections, or abnormal resource consumption from deployed models should trigger alerts and investigation.
Limit execution capabilities within model containers. Consider what level of code execution is actually necessary for legitimate model operation, and restrict everything beyond that scope. Sandboxing and containerization are starting points, not complete solutions.
Implement robust authentication and authorization for all model APIs. Even though these are user-deployed models, access should be tightly controlled and auditable.
Conduct regular red team assessments specifically focused on your ML infrastructure. Traditional penetration testing may not uncover the unique attack paths available through ML platforms.
Generative AI Security: The Broader Lesson
The security community’s focus on LLM vulnerabilities is understandable and important. Prompt injection, model poisoning, and adversarial attacks on AI systems are real risks that deserve attention and resources.
But as this engagement demonstrated, the attack surface for AI extends far beyond the models themselves. The platforms that enable ML development and deployment create their own set of risks—risks that can provide direct access to an organization’s most sensitive resources.
As businesses continue to embrace ML and AI capabilities, they need to think holistically about security. That means not just protecting against prompt injection and model manipulation, but also securing the infrastructure that makes modern ML possible.
Attackers already know this. They’re not debating prompt engineering techniques—they’re registering user accounts and looking for what those accounts can reach. The question isn’t just whether your ML models are vulnerable. It’s whether your ML platform is accidentally functioning as a VPN into your internal network.
Frequently Asked Questions
What are the main security risks associated with AI?
The primary AI security risks include adversarial attacks that manipulate AI algorithms to produce incorrect outputs, data poisoning during AI training phases, and model theft where attackers steal proprietary machine learning models. AI systems are also vulnerable to prompt injection attacks in generative AI applications, where malicious inputs can cause the AI to behave unexpectedly or reveal sensitive information. Additionally, AI-powered systems can amplify existing cybersecurity vulnerabilities and create new attack vectors that traditional security measures may fail to detect.
How can AI systems be exploited in cyberattacks?
Cybercriminals can exploit AI systems through adversarial examples that fool machine learning models into misclassifying threats, allowing malicious content to evade detection. Attackers may also target the AI training data to poison learning models, causing them to make incorrect decisions in production environments. Furthermore, AI applications can be compromised through injection attacks that manipulate generative AI models to produce harmful outputs or leak confidential information.
How can AI systems be used to enhance cyberattacks?
Malicious actors leverage AI tools to automate and scale cyberattacks, using machine learning algorithms to identify vulnerabilities faster than human analysts. AI-powered attacks can generate sophisticated phishing emails, create deepfake content for social engineering, and develop polymorphic malware that constantly evolves to evade detection. Generative AI models enable attackers to produce convincing fake identities and documents, making it increasingly difficult for traditional cyber security measures to distinguish between legitimate and malicious activities.
How can organizations mitigate AI security risks?
Organizations should implement robust AI security frameworks that include regular testing for adversarial attacks, secure AI training pipelines with data validation, and continuous monitoring of AI model behavior in production. Essential mitigation strategies involve maintaining human oversight over critical AI applications, implementing input validation to prevent injection attacks, and establishing incident response procedures specifically for AI security threats. Additionally, companies must ensure proper access controls for AI systems and regularly update their AI tools to address emerging threats and vulnerabilities.
What is AI Security?
AI security encompasses the protection of artificial intelligence systems, data, and infrastructure from cyber threats while ensuring AI applications operate safely and reliably. It involves securing AI algorithms against adversarial attacks, protecting machine learning models from data poisoning, and preventing unauthorized access to AI training data. AI security also includes implementing safeguards in generative AI security to prevent misuse and ensuring that AI use in cybersecurity doesn’t introduce new vulnerabilities to organizational systems.
