Think like a hacker and ask yourself how fast your passwords might be able to be cracked based on their structure.
When hackers or penetration testers compromise a system and want access to clear text passwords from a database dump, they must first crack the password hashes that are stored. Many attackers approach this concept headfirst: They try any arbitrary password attack they feel like trying with little reasoning. This discussion will demonstrate some effective methodologies for password cracking and how statistical analysis of passwords can be used in conjunction with tools to create a time boxed approach to efficient and successful cracking.
Update 02/11/2016: Statistics based password cracking rules released for Hashcat (Contact Praetorian for more information)
Why Is This Important?
Password cracking is a dying enterprise. Users are required to create ever more complex passwords, and some back-end developers are starting to utilize mechanisms such as Bcrypt to replace standard hashing functions. Bcrypt hashes take a drastically longer period of time to generate, and because of this, passwords become significantly more difficult to crack. Crackers need to generate hashes very quickly to effectively crack passwords, and thus Bcrypt is a very powerful tool against such attacks. To illustrate this example, a password cracker made from a 25-GPU cluster presented in 2012 was able to achieve an NTLM hash generation speed of 350 billion hashes per second compared to a Bcrypt hash generation speed of 71,000. Using this as a model of comparison, for every single Bcrypt hash generated, 5 million NTLM hashes can be generated. When faced with Bcrpyted algorithms, hackers must make much more calculated guesses against passwords and cannot rely on using brute force for every possibility.
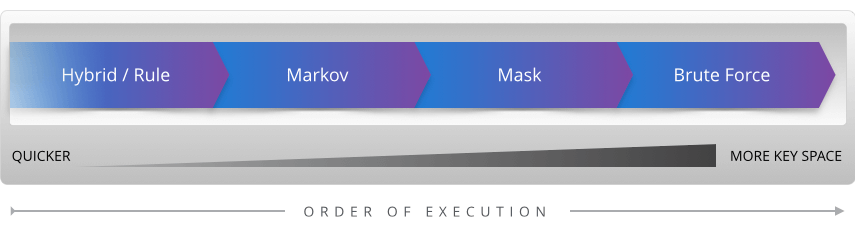
Password attack Description=============== ===========Dictionary Checks each word in a wordlistHybrid/rules Augments wordlists by adding characters before/after wordsMarkov Uses machine learning to assemble possible guessesMask Attacks the structure of a password’s character compositionBrute Force Tries every possible combination of characters
Note: If an attacker knows the length of a password is significantly short enough such that brute forcing the key space would not take very long there is no need to take incremental attack steps.
The Timeline
Time efficiency becomes the key component of successful password cracking. While it would be nice to cover the entire key space of what a user’s password might be, the time needed to do so is often not feasible. So when cracking, it is important to try the most time effective attacks first and if unsuccessful, move on to slower password attacks that cover more key space. The quickest method is a simple dictionary attack based on popular user passwords and previous password dumps. From there, manipulating the dictionary to add digits or symbols on the end or changing letters around should be attempted. This is known as a hybrid or rules-based attack. Next, using machine learning capabilities to generate possible passwords could be attempted. Markov chaining is a great example of this. By combining common elements that exist within English to form words (e.g., “ing,” “er,” “qu”), it is possible to generate good guesses for passwords, such as the password Password1234 below. Although this particular password would be easy to crack using any of the methods, we will use Password1234 for simplicity across all attack vectors.
Pa + ss + word + 1234
Finally, targeted brute force attacks, called mask attacks, cover all the key space of a given password based on a password structure. By “structure” of a password I am referring to the types of characters and ordering used to create the password. For instance, Password1234 has a “structure” of a capital letter, followed by seven lowercase letters, followed by four digits (notated as ullllllldddd).
Lower case alpha (l), Upper case alpha (u), Symbol (s), Digit (d)
So if an attacker decided to create all possibilities of character combinations using that structure, he or she would eventually find the password Password1234. The question for the attacker then becomes: What structure should be targeted first when attacking a set of hashes?
Statistical Analysis
To help answer this question, I conducted some statistical analysis on popular password dumps to see if there were password structures that were more prevalent than others and to what extent that was true. The sample size of over 34 million publicly exposed passwords included famous password dumps such as RockYou, LinkedIn, phpBB and others.
=======================================Total Passwords Analyzed: 34,659,199=======================================Rockyou 14,344,39110-million-combos 10,000,000LinkedIn 8,616,484eHarmony 1,513,935phpBB 184,389=======================================
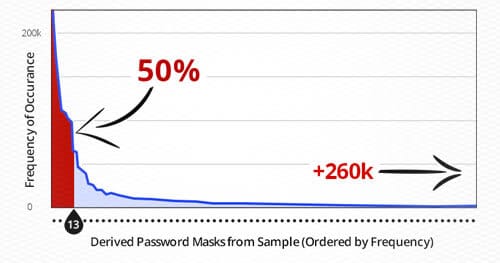
Below is a graph that displays the frequency of a mask structure against each unique mask. The red line indicates the 50% line, which occurs after the 13th most frequently occurring mask.
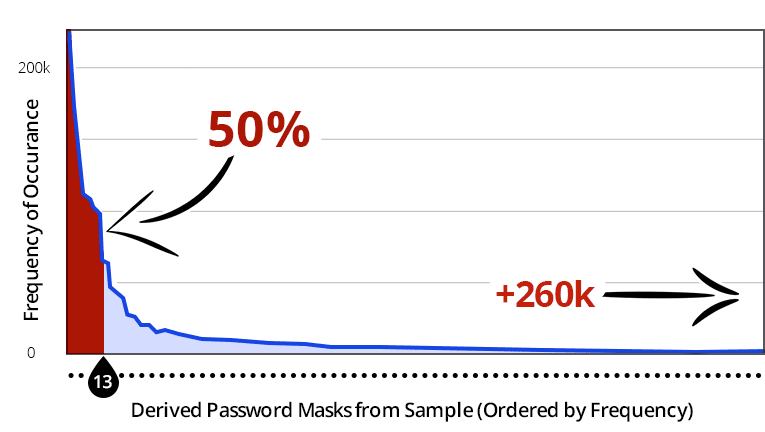
This means that the top 13 unique mask structures make up 50% of the passwords from the sample. Over 20 million passwords in the sample have a structure within the top 13 masks. These results are quite shocking with regard to the universality of structured passwords. The other 50% exist within the long right tail, which has been curtailed in this graph. In fact, of the 260,500 unique masks, only 400 are shown in this graph. This concept of universally structured passwords is incredible; however, it’s not too surprising when you consider how users create and remember their passwords. Based on analyzing the data, there are logical factors that help explain how this is possible. When users are asked to provide a password that contains an uppercase letter, over 90% of the time it is put as the first character. When asked to use a digit, most users will put two digits at the end of their password (graduation year perhaps). The next most popular choice is to end the password with four digits (likely the previous or current year). The next most popular in this case has one digit at the end, and after that three digits at the end. Commonalties in structure such as these allow attackers to predict what the structure of a user’s password will most likely be.
Statistical Hybrid – Speeding Up
Using this knowledge of structures, it is safe to assume that a user will more than likely set his or her password as potatoes than pwivwdhp (random letters) even though they both begin with p and have nine letters. Therefore, we are assuming that given a password structure, if we see consecutive letters, it is more than likely a word. This is a very helpful assumption for crackers because it eliminates an enormous amount of key space. This then becomes a hybrid attack utilizing the statistical significance of universal password structures.
Efficiency and Time Boxing
Oftentimes, as penetration testers, even if we compromise a set of hashes, we may not have time to crack all of them. However, compromising them may help escalate access into the system and result in more helpful findings for the client. Therefore, when cracking passwords, it can be useful to determine how much time will be allotted for cracking a set of hashes. Using the structures that were found in the previous analysis, an attacker could determine that he or she wants to cover the top 10 popular structures based on the password complexity requirements sorted by quickest time to complete. Finally, the attacker may time box his or her approach by not spending any more than an hour to execute the cracking. This was identified in a recent penetration test in which hashes were obtained. Below is a snapshot of the results with a CPU-based cracker.
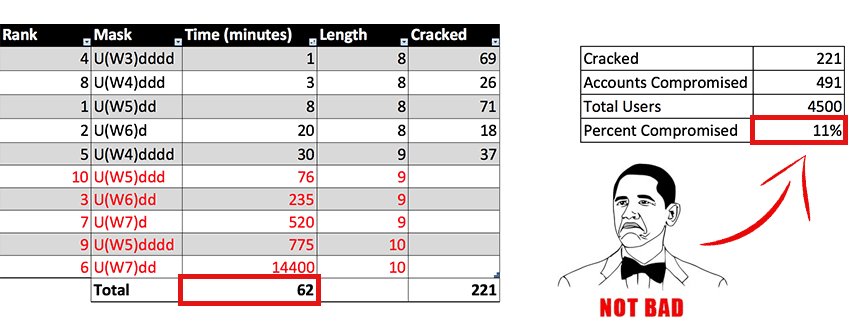
In this case, the quickest structure to complete was U(W3)dddd, which we define as an uppercase letter followed by three lowercase letters (“W” stands for “word”) and then four digits. There were 69 passwords in the hash set that matched that structure, and my standard CPU was able to traverse all possibilities of that structure in one minute. We stopped cracking at 62 minutes, and the crack yielded 221 unique cracked hashes, which matched 491 accounts and resulted in a total of 11% compromise. The reason there is a large difference in number of passwords cracked and accounts compromised is because office settings tend to result in people using common passwords. If an attacker determines a common password is being used in an environment, then all of the users with that same password will also be compromised.
Although a hybrid attack or rules based attack such as best64 could have cracked several of these passwords more quickly, attacking the structure of the password allows us to cover more key space. If quicker attacks proved unsuccessful in compromising a target hash, this approach is a time effective next step. Also it is important to keep in mind that this example was done on a fairly mediocre CPU and that doing the same attacks on a power GPU could cut this time down to literally seconds. Therefore the exact timing is not as important as the theory of efficient execution.
Targeting
Statistical analysis helps us attack common password structures universally; however, some tools exist to help target specific application. Tools such as CeWL can scrap words from a webpage and be used to generate a wordlist or dictionary that is specifically aimed at a company. This works because companies tend to use passwords that deal with their industry, company or line of work. Also, since we determined that common passwords are popular within working environments, it is also possible to take the passwords that have already been cracked and use them as a basis for other passwords, which may be similar. For instance, if we found that “AcmeCorp1234” was a password for one user, we may put “AcmeCorp” into a new wordlist, throw it into a rule set and find that someone else has the password “AcmeCorp@2015“. This concept of using cracked base words such as ‘AcmeCorp‘ and mangling with the surrounding characters is an extremely effective when cracking hashes dumped from a corporate environment, which goes back to the concept of password reuse. Based on penetration tests we conduct, this is best used for cracking the last 20% of un-cracked hashes.
Pruning dictionaries so that all the passwords that are guessed conform to the requirements set out by the application is also important so that no time is wasted on guessing passwords that are not possible due to length or character composition.
Putting It Together
Starting from the quickest attack, covering the least amount of key space (standard dictionary attack) going to the slowest and largest key space (pure brute force) is the most ideal progression for considering the time allotted for an attack. Thus an attacker should implement a standard methodology that takes this into consideration. If the accounts that the attacker wants to compromise are completed in the first stages, then there may be no reason to continue using the other attacks; however, in many instances if there is a targeted account, a simple dictionary attack may not be sufficient – or perhaps the attacker just wants to compromise as many accounts as possible – and thus hybrid attacks and targeted brute force attacks using statistical structures may be needed. Thus establishing a methodology is critical to successful cracking, which can include the methods mentioned previously as well as some automated processes. Recent tools such as PRINCE can help facilitate password cracking. Developing a tool belt of tricks such as PRINCE to try within the methodology is important, but understanding the functionality behind the tools and not relying on them completely will make cracking much more effective.
The Defense – How to Combat Statistics
With the analysis done with these passwords, it is possible to determine the most popular structures given a required level of complexity. Therefore, developers should perhaps implement controls that stop users from using some of these very popular structures in an effort to flatten the curve of the previous graph. The issue with this idea, however, is that without an easy structure, users may find it difficult to remember their passwords. I would recommend using password managers that require two-factor authentication. These applications will generate and store all your passwords for you so that memory is not an issue. The passwords they generate are random in structure and can be as long as the application will allow. As I mentioned before, Bcrypting passwords is another very effective way to slow an attacker from a development prospective. Finally, implementing policies within the office that helps users know the dangers of sharing passwords or reusing passwords is a successful stride in the right direction, even if users don’t always comply. Though they most likely won’t comply all the time, it is an effective control.
Conclusions and Takeaways
Password cracking can be a nebulous concept. As cracking becomes more difficult, targeted attacks based on efficiency are needed, and a personal cracking methodology should be established. Throwing away money in attempt to eventually improve the rate of hash generation is not worth the cost. Therefore, implementing a methodology and a streamlined process using statistics and tools as a means of attack can facilitate the cracking of passwords. Developers can institute controls to combat this, and users can use secure password managers to minimize the effectiveness of these attacks; however, such implementations are not very popular yet. Statistical attacks on passwords are currently effective in terms of quantity cracked and time efficiency. Think about your own passwords and ask yourself how fast they might be able to be cracked based on their structure and what controls within your office may lead to an attacker compromising a user’s account.