Overview
The topic of responsible red teaming has become a frequent topic of discussion in recent months. One such debate has revolved around the theme of securely managing red team infrastructure. The security of red team infrastructure is paramount given the sensitive nature of the data stored on command and control servers and the access an attacker would gain from the compromise of these systems.
Background Discussion
Many individuals within the red teaming and information security community have contributed their perspectives on red team infrastructure management. Notable examples include Tim MalcomVetter from the Walmart Red Team [1][2] and Brady Bloxham from Silent Break Security [3] . At Praetorian, the topic of red team infrastructure and security is a topic of great interest and conversation. This post is our contribution to the ongoing discussion on responsibly managing red team infrastructure and is high level in nature. Therefore we will not be discussing specific implementation details in-depth within this article. Our goal is to release further posts in the future that explain particular implementation details.
Our Approach Using Google BeyondCorp
Our primary focus is on implementing a Google BeyondCorp architecture while building off of managed services and existing solutions. By using managed services, we can reduce costs through outsourcing and automation while focusing on core competencies. We define these cost reductions both in terms of time as well as financial resources. By leveraging managed cloud services, we only pay for infrastructure when there is an active red team operation with the infrastructure expense serving as a primarily fixed per-project cost. Additionally, economies of scale allow cloud providers such as Okta, Cloudflare, and Google to provide backend infrastructure services for red team engagements at a significantly lower cost than an internally developed and managed solution.
To achieve this architecture, we are primarily leveraging the Google Cloud Platform (GCP) service and the Cloudflare Access solution provided by Cloudflare. Google Cloud Platform (GCP) is a comparable solution to Amazon Web Services or Microsoft Azure. Cloudflare Access is a managed service that offers many components of a BeyondCorp architecture as a service. The primary functionality provided by Cloudflare Access is the ability to use the solution as an Identity Aware Proxy (IAP) for controlling access to infrastructure. For instance, the Cloudflare Access solution acts as a reverse proxy in front of our internal Gitlab service. Access forces users attempting to access the backend application to authenticate through an SSO provider. Access also supports acting as a centralized certificate authority for controlling SSH access to servers. Users first authenticate through an identity provider to obtain a time-limited signed SSH key to authenticate against a system.
For authentication, we leverage Okta as a centralized authority for authentication and access control decisions. Leveraging Okta allows us to enforce MFA using FIDO/U2F authentication when accessing red team infrastructure through SSO with Cloudflare Access and GCP. The combination of Cloudflare Access and Okta allows us to enforce a strong user identity and authentication model while enforcing multifactor authentication to all red team services.
Red Team Process Improvement Methodology
In many ways, our process of improving the red team service is metaphorically like “building the plane while flying it.” What we mean by this is that our typical approach consists of two to three-week sprints of internal project time to make significant feature changes and improvements. These improvements must be tangible enough that we can begin making use of them in any future red team engagements. This methodology forces us to focus on making incremental improvements while still maintaining a stable toolset and avoid over-engineering solutions. Immediately adopting and making use of the automation tooling allows us to identify issues and obtain feedback quickly.
Outside of the allocated time for development, we will continually make incremental improvements to our tooling during the red team engagement, including minor bug fixes or feature changes. Significant new feature ideas, as well as over-arching themes/epics, are added to our prioritized backlog. The highest priority tickets are selected and used to create an internal project proposal. This process works well as it allows us to adopt a culture of continuous improvement while allocating dedicated time for larger projects and maintain accountability for tasks.
DevOps and DevSecOps Process Benefits
Leveraging Terraform and Ansible with managed cloud services allows us to automate,end-to-end, the red team infrastructure provisioning process while following best practices related to DevOps. These practices include managing infrastructure as code in git repositories. The infrastructure as code workflow enables us to maintain predictable and repeatable deployments while minimizing the risk of human error. It also allows for security code reviews to be conducted against the infrastructure deployment code.
Another aspect of red team infrastructure security is identity and access management. An operator should only be able to access infrastructure that is related to projects they are currently working on. Engineers working on unrelated projects or within other departments should not be able to access red team systems for that particular project. To accomplish this level of segmentation, we create a separate isolated GCP project for every engagement. Using independent GCP projects for every red team also has the added benefit of allowing us to start from a known good state. Any configuration errors made during a previous deployment are not going to affect future ones. Additionally, we create different access groups within Cloudflare Access to limit SSH access to only systems related to a project an operator is currently working on.
Balancing Outsourcing with Security
The shared responsibility model for cloud infrastructure allows us to outsource many of the aspects related to infrastructure management that are unrelated to conducting red team engagements.
Cloud services also allow us to scale deployment to support multiple active or concurrent operations. A unique issue for red teams is the nature of the work can lead to abuse reports. This unique challenge can lead to problems related to potential violations of provider terms of service. It is essential to communicate with any managed providers that could receive abuse reports to alert them of your activities. Many cloud providers are willing to implement exceptions for reputable security companies conducting penetration testing or red team exercises. Another critical aspect of leveraging and selecting managed services is security. Trust is, of course, key in security, and outsourcing infrastructure management has security implications.
Addressing Red Team Specific Challenges
Outside of the general issues related to infrastructure and access management, many red team-specific challenges exist. For instance, we need to manage a network of redirectors spanning multiple CDNs and providers while preventing the blue team from cross-correlating our activities and attributing us. In this regard, automation plays a vital role, and the ability to spin up isolated infrastructure instances ensures that there is not any overlap between different operations or campaigns.
There exist some red team-specific benefits to adopting a BeyondCorp architecture as well. For instance, eliminating the requirement of connecting to a VPN to access infrastructure means that operators no longer have to manage connections between the attributable corporate VPN and non-attributable proxy systems.
Reference Architecture
We have developed a reference architecture for using BeyondCorp for red team infrastructure management. This architecture represents a standard deployment that works for most red team engagements. It aims to serve as a high-security environment with secure ingress and egress controls, multi-factor authentication, network segmentation, endpoint monitoring, and centralized monitoring and detection. The diagram below outlines this architecture.
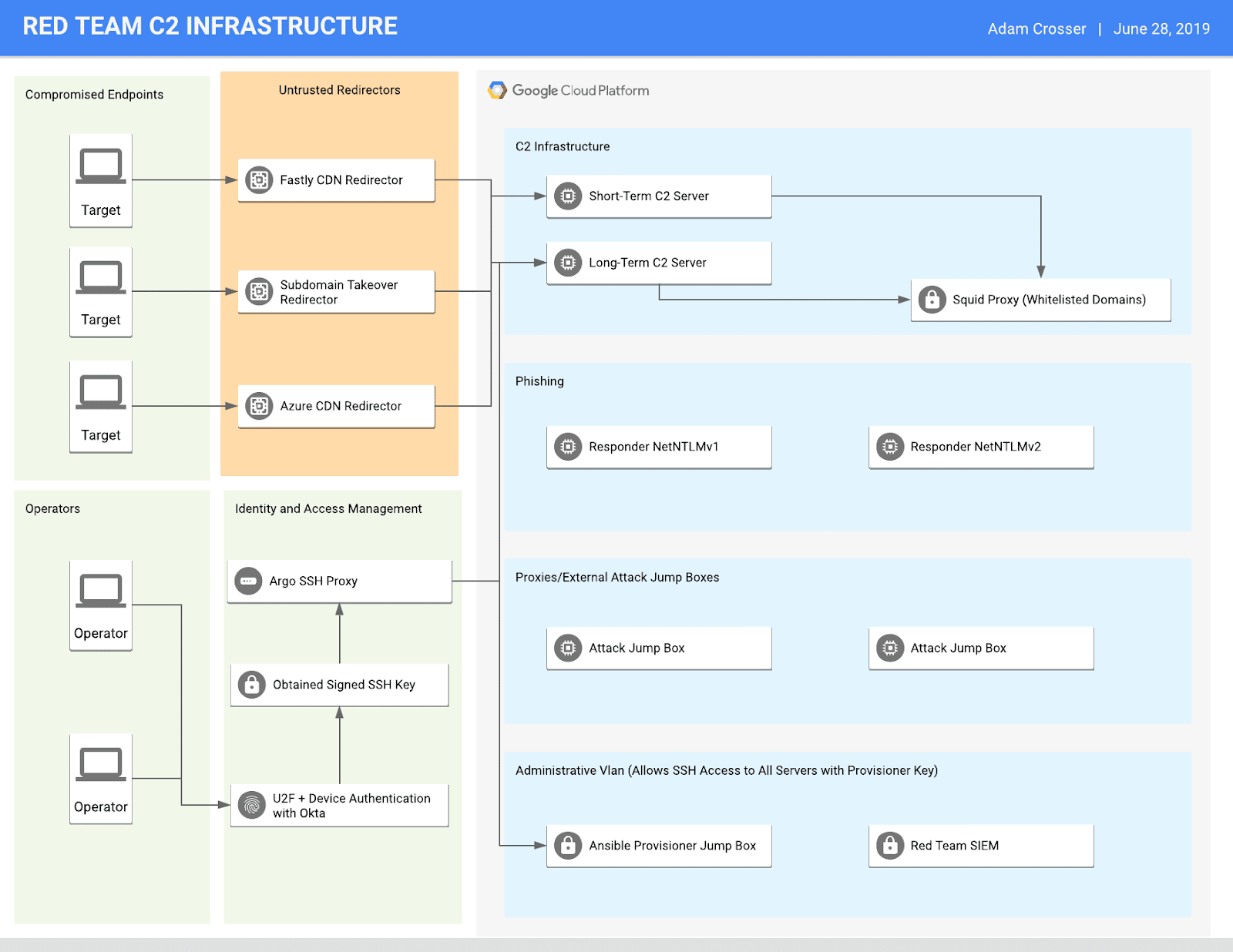
In this diagram, you can see that operators connect to backend infrastructure using Okta with FIDO/U2F authentication to obtain a signed SSH key. Traffic is then routed through Cloudflare’s Argo Tunnel to reach the backend hosts. Argo serves as the managed networking component of Cloudflare Access, creating a connection between our GCP resources and the Cloudflare IAP. The internal GCP network consists of four different subnets, and communication (even host to host) is denied by default unless explicitly allowed. It includes a management VLAN with a dedicated host for Ansible deployments. A red team SIEM (Graylog) receives logs from hosts to maintain a record of operator actions and host-based telemetry. Operators connect to jump hosts to run scanning and enumeration tools. These jump hosts may themselves connect to a disparate set of proxies (or using e.g. AWS lambda functions) to mask their activities.
The phishing network houses systems used for phishing attacks. The idea is that operators can spin up these types of phishing servers automatically as they need them and destroy them after the campaign.
The command and control network is only accessible from the provisioner jump box or Cloudflare Access + Okta authentication. Due to the sensitive nature of this network, the goal is to restrict all egress traffic to only the necessary services.
Only allowed redirectors from specific IP addresses are allowed to connect to the command and control server backend. We assume that the redirectors have been compromised and are actively tampering with traffic. Cobalt Strike’s Beacon embeds a public/private key pair in every payload so that even if the redirectors are compromised, an attacker could not gain additional information about the actual command-and-control traffic [4]. Any custom implants in development will also include this functionality as well.
We leverage a diverse set of redirectors spanning many services. Three examples would be Fastly, Azure, and subdomain take over redirectors (e.g., Pantheon).
We have completed phase one implementation and began using this architecture successfully during several recent engagements. Continual work is underway to finalize certain aspects of the architecture (e.g., the Squid proxy component and enhanced monitoring/alerting) for the phase-two implementation.
Internal Code Review and Penetration Testing
After completing our phase two automation and BeyondCorp implementation work, we plan on leveraging internal expertise to conduct a full-knowledge security review against our solution. The goal for this audit will be for it to be external to the red team while leveraging internal expertise. It will encompass an examination of our cloud security practices and infrastructure management tooling to enumerate potential security risks comprehensively.
Conclusion
Red team infrastructure management is an area that we are continually working to develop and improve on at Praetorian. As we continue to make improvements and refine our infrastructure management methodologies, we plan on continuing to share our knowledge and experience in this area. We hope that other red teams will be able to leverage many of our ideas to improve their practices in infrastructure management and security. Any comments furthering the discussion of this matter are encouraged. Infrastructure management and security are important to us, so any feedback, alternate opinions, or constructive criticism is encouraged.
References
[1] https://medium.com/@malcomvetter/responsible-red-teams-1c6209fd43cc
[2] https://medium.com/@malcomvetter/safe-red-team-infrastructure-c5d6a0f13fac
[3] https://silentbreaksecurity.com/modern-red-team-infrastructure/
[4] https://www.cobaltstrike.com/downloads/csmanual40.pdf
