
In part one, we covered setting up a development environment for working with LLVM and developed a simple pass that inserted junk code into binaries during compilation to hinder signature-based detection and manual reverse engineering efforts. In this article, we develop a more complex pass that automatically encrypts string literals during the compilation process by manipulating the LLVM IR.
Where is String Obfuscation Used?
String obfuscation is a technique that is commonly used by malware to hinder manual reverse engineering and analysis by defenders. During reverse engineering, it is common to use strings embedded within the target binary to identify relevant functionality during analysis. For instance, a malware analyst might pivot off of references to a user agent string constant in a binary to identify command and control related code within a malware sample. Additionally, analysis of strings embedded within a binary is standard during dynamic analysis as in many instances, it is possible to determine information about the functionality and workings of a malware sample by merely using the strings command.
Because of this, malware developers commonly encrypt string literals within binaries to hinder this type of analysis by security teams as well as to evade signature-based detection targeting string literals. The encrypted strings get decrypted at runtime in-memory when referenced during program execution.
Outside of the realm of malware analysis, it is also common for this type of obfuscation mechanism to be used to hinder reverse engineering of applications for commercial purposes such as intellectual property protection and digital rights management (DRM).
Designing the String Encryption Mechanism
We have several options when it comes to implementing the automated string encryption mechanism. One option would be to encrypt every string literal within the binary and then call the decryption routine at the beginning of main. The advantage of this approach is that it is very stable and simple to implement. However, the disadvantage is that every string within the binary is stored in plaintext in memory, making it relatively easy for an analyst to obtain every decrypted string at once.
An alternative approach would be to encrypt every string and only decrypt the string when referenced during program execution. Once the program no longer uses the string, it should be re-encrypted to avoid unnecessarily storing cleartext strings in memory. A disadvantage of this approach is that it can be challenging to track when a program no longer references a string. This reference tracking problem opens up a risk of the obfuscation engine, inserting potential errors or bugs into the compiled code or violating assumptions made by the programmer.
One way to implement the approach mentioned previously would be to move global string constants into the IR for a specific function itself. Then the string could be decrypted and written onto the program stack. When the function returns, the string would effectively be deallocated and overwritten by subsequent function calls. The code given below shows what this transformation would look like at a high level. It starts by allocating a buffer on the stack to store the string and then writes each character into the buffer.
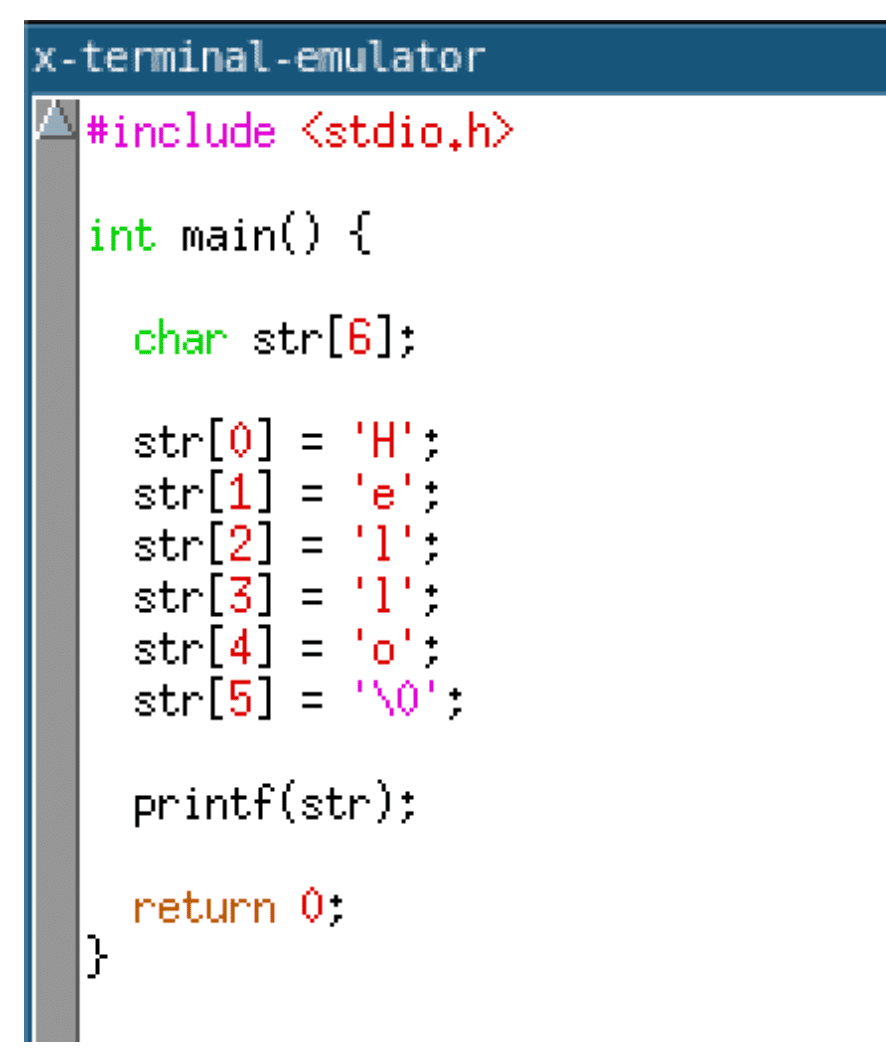
The generated code, when compiled with GCC, results in a series of move instructions that write the string into the allocated stack buffer. A disassembly of the function when compiled with GCC is given below.
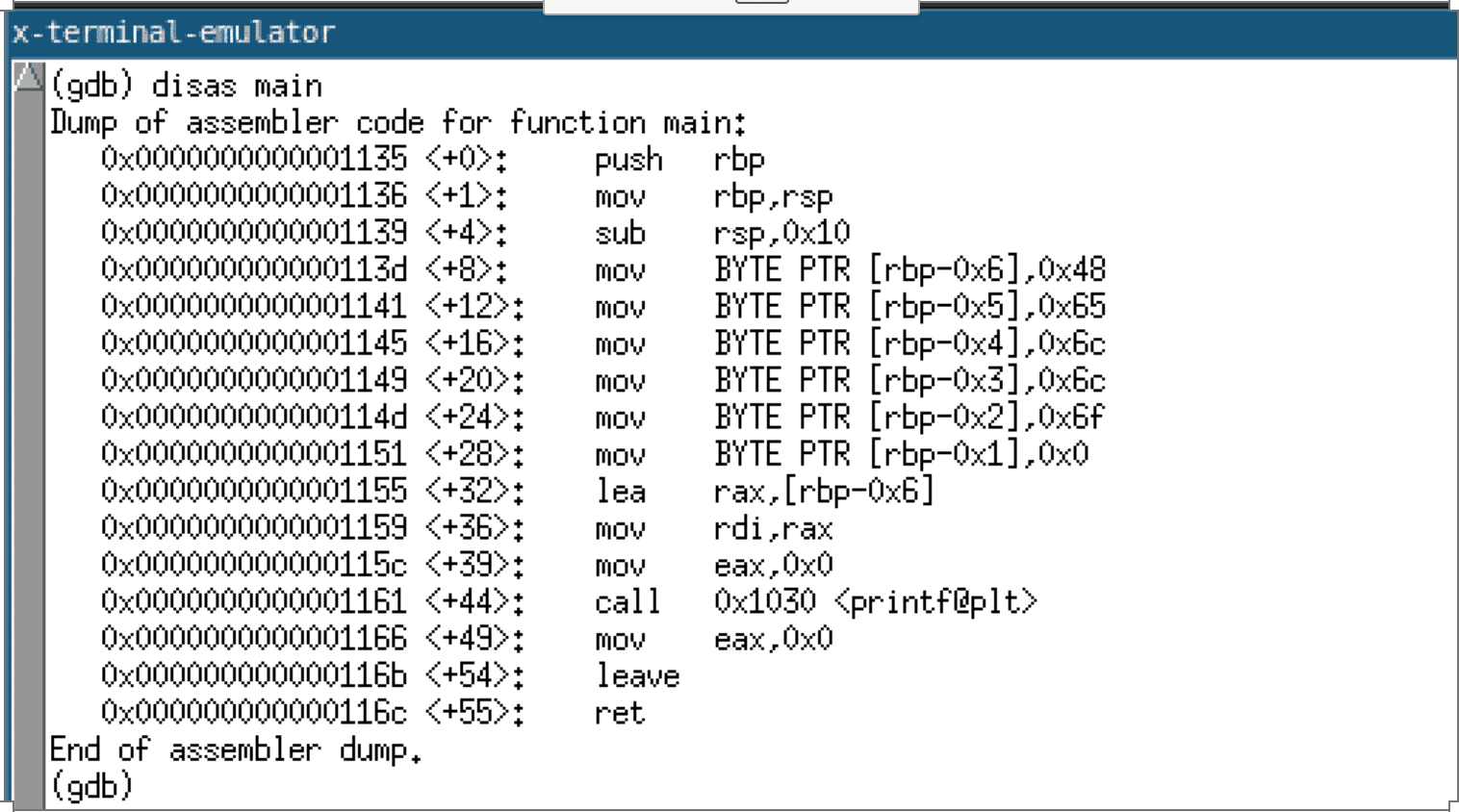
As mentioned previously, it is imperative to note that this transformation of a global variable to a stack-based variable is not without potential undesired consequences. The string constant now is deallocated when the function returns, violating assumptions made by the programmer about the scope of the string constant. For example, the programmer may invoke a function with a pointer to the now stack-based string constant. This function may store a reference to this string constant in a struct or global variable. If this pointer is dereferenced after the parent function returns, the behavior is undefined since subsequent function calls could allocate the stack space previously used to store the string constant.
Several approaches are possible when attempting to address these issues. The first potential solution would be to educate the programmer on the workings of the code obfuscation engine and have them write code in a manner that avoids causing this issue to arise. The downside to this approach is that it is not suitable for large legacy codebases. An alternative approach would be to support both an opt-in or opt-out approach for this type of obfuscation on a per-string basis. For instance, the programmer could specify either specific strings to be encrypted or specific strings that should not be encrypted. A third approach would be instead of allocating memory on the stack to allocate it on the heap. This change would prevent the assumptions made by the programmer on the lifetime of string constants from being violated; however, the downside of this approach is that once a string is decrypted, it remains in cleartext in memory for the duration of program execution.
Due to the string obfuscation pass being a proof of concept utility, I have elected to opt for the first method. We assume that the programmer is aware of the workings of the code obfuscation engine to avoid triggering this edge case. This solution is not optimal for large legacy codebases or use in a commercial-grade code obfuscation tool.
Developing the LLVM Pass
Now that we have selected a string obfuscation algorithm, it is time to begin the development of the string obfuscation pass. First, we need to loop through each global variable in a given source code file and determine if it is a string constant that is eligible for replacement — the code given below implements this logic.

After building a list of global variables, we iterate through every instruction within every function in the code. We then examine the operands within these instructions to identify any operands referencing a global variable within our substitution list – the code given below implements this logic.
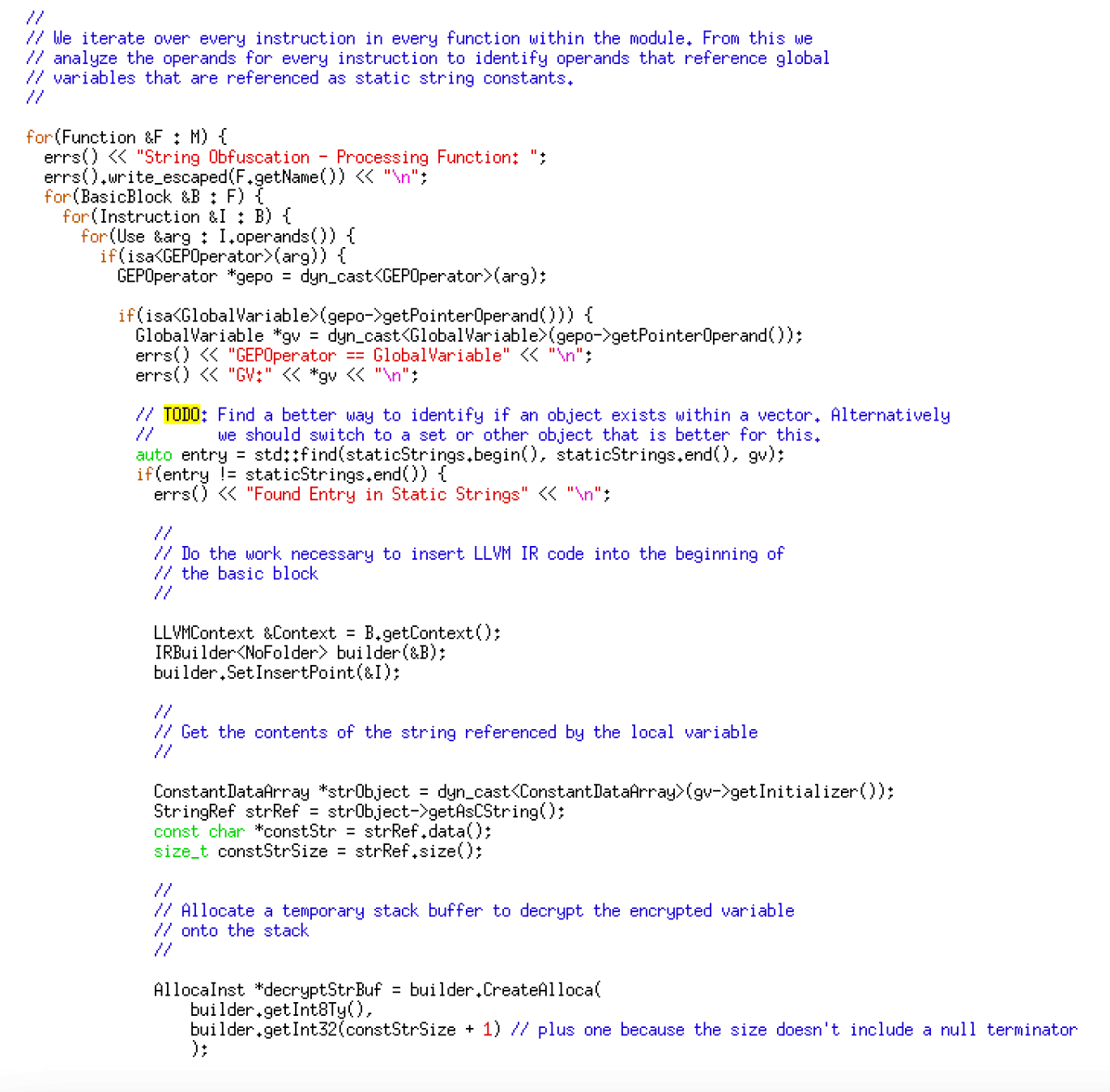
Next, we generate code for an XOR-based decryption routine that writes the encrypted string onto the stack while embedding the ciphertext within the IR code. The code given below generates the IR code for decryption.

The decryption code is inserted before the instruction that references that string literal and the operand modified to reference the local stack variable instead of the global variable. Finally, once every reference to the string literal has been replaced, the final loop deletes the global string constant variable as they are no longer needed — the code given below implements the replacement and deletion logic.

Using the String Obfuscation Pass
The steps for using the string obfuscation pass are the same as those outlined in part one. The one difference is that when invoking the opt command, you need to specify the -stringobfs parameter.
In this instance, we are compiling the program given below to demonstrate the effects of the string obfuscation pass.
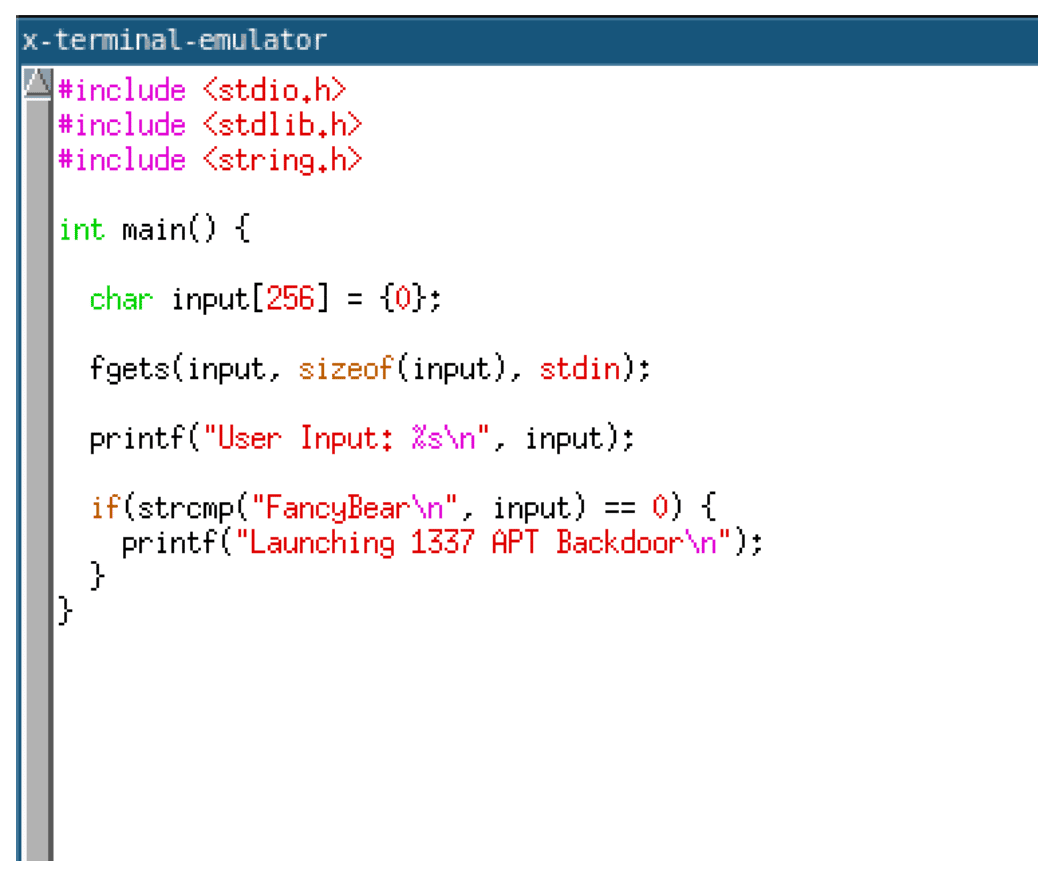
Examining the compiled code, we can observe the string decryption XOR routine decrypting the string and writing it onto the stack. The image given below shows a disassembly of this routine.
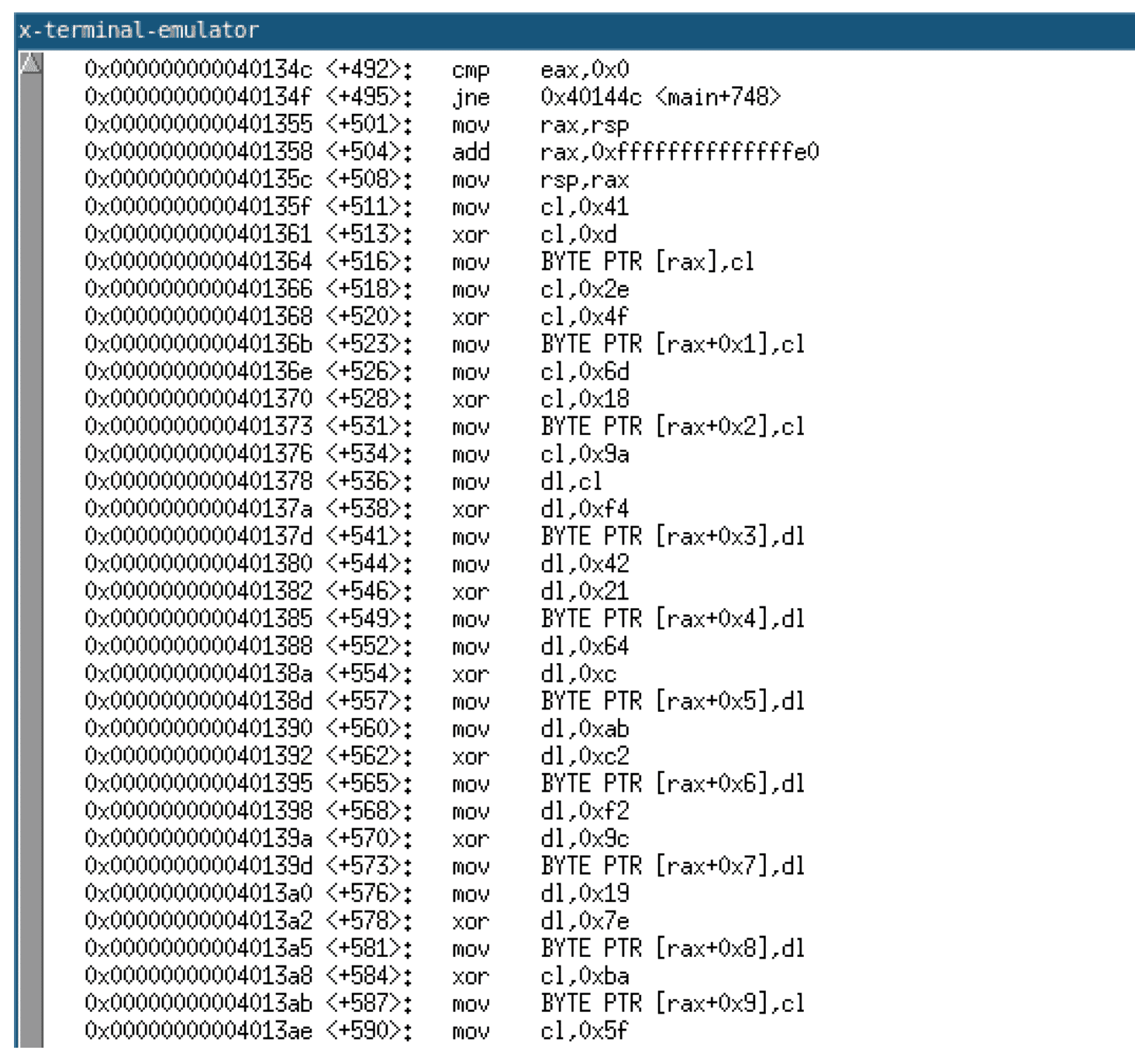
If we examine the strings within the compiled program, we can observe that none of the string literals used in the program are visible.

However, if we examine a version of the same program compiled with GCC, we can see that as expected the strings are not encrypted and visible when running the strings command.

Conclusion
Code obfuscation has numerous use cases ranging from copyright protection of software, intellectual property protection, digital rights management (DRM), and its use by malware authors to hinder reverse engineering of malicious code and evade signature-based antivirus software.
Due to its extensible and modular architecture, LLVM provides the perfect foundation for the development of code obfuscation tools. However, due to the changing nature of the LLVM API and the lack of backwards compatibility, continual maintenance is required to maintain compatibility with current LLVM releases.
On the Praetorian red team, we have invested resources into improving code obfuscation to hinder analysis of compiled code and to simulate the evasion techniques leveraged by real-world adversaries more accurately.
The code obfuscation passes presented in this article should be considered as proof-of-concept grade tools and should not be used in commercial software applications without adequate testing.
