What started as a small curiosity during a code review ended with a CVE and some hard questions about agentic AI security.
A while back, I was using Claude Code to audit a codebase when I noticed something odd. When pulling references and documentation, it explicitly asked for permission for some domains but not for others, like docs.python.org or modelcontextprotocol.io.
This made me curious, so I started investigating. I figured Claude Code was doing this deterministically by maintaining a list of hardcoded domains. At first, I just wanted to see what this list was. I got the Claude Code executable and started reverse engineering it. The executable itself is a heavily obfuscated Node.js program, so I used WebCrack to deobfuscate it. The executable itself is a heavily obfuscated Node.js program, so I used WebCrack to deobfuscate it. I searched for the whitelisted domains, which helped me identify the code responsible for domain verification. Ironically, I ended up using Claude Code during this process to clean up the code further.
A Closer Look
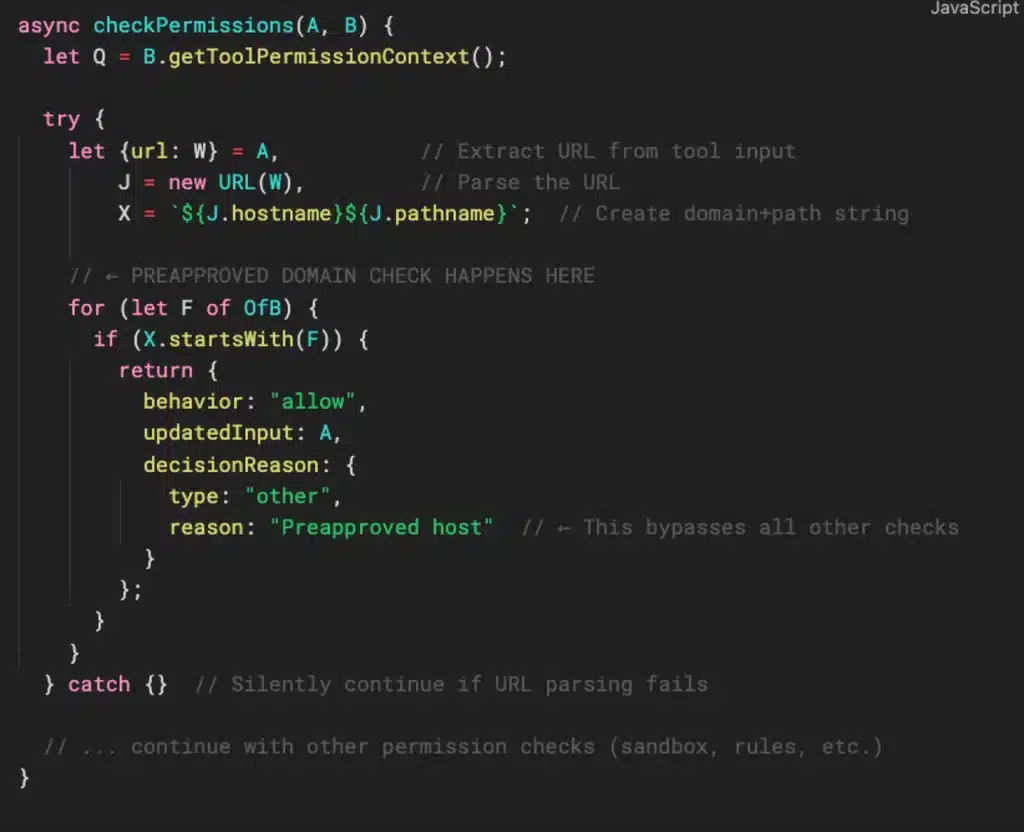
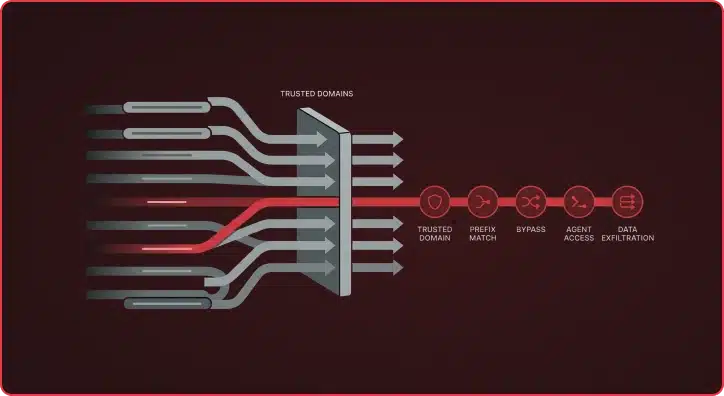
While trying to understand how the domain verification code worked, I found that it used startsWith() to check domains against the whitelist. This method only checks whether a string begins with a given prefix, so domains like modelcontextprotocol.io.attacker.com could bypass verification entirely. It’s a simple bug, but with serious implications given the level of access Claude Code has.
To test this, I spun up an EC2 instance and registered the subdomain modelcontextprotocol.io.attacker.com, pointing the DNS to my server. I used Let’s Encrypt to set up TLS since Claude Code only makes HTTPS requests by default. From there, I created a basic POC repo with malicious instructions. Claude Code exfiltrated data from the victim’s machine and sent it to my server without user consent.
After reporting this to Anthropic, they acknowledged the issue within a day and deployed a fix soon after. Anthropic assigned this vulnerability CVE-2026-24052.
Familiar CVEs and Systemic Patterns
I was really surprised that a company like Anthropic could let this slip by, so I decided to dig deeper. It turns out researchers had already found this exact type of vulnerability in Anthropic’s Filesystem MCP Server (CVE-2025-53110). This vulnerability suffered from the same flaw: it relied on startsWith() for path validation. Attackers could bypass directory restrictions by accessing file paths that simply began with an allowed prefix.
Claude Code’s command validation relied on regex blacklists to block dangerous commands. This led to multiple command injection vulnerabilities, independently discovered by Cymulate and GMO Flatt Security. It indicates another systemic anti-pattern across the codebase.
Given that leading AI companies have stated that all, or at least most, of their code is now AI-written, we are likely to see more incidents like these, where a single manually introduced anti-pattern is amplified across the codebase by an LLM assistant. However, even as models are retrained on better data, novel vulnerabilities will continue to appear, ensuring that training data is always behind the current threat landscape, making human-driven offensive security testing irreplaceable.
The Agentic AI Security Model — and Why It’s Failing
The reality is that agentic AI security is still immature — newer AI coding tools lack the security posture to implement effective sandboxing. This is particularly alarming given how rapidly these tools are entering development workflows. Some tools explicitly instruct developers to run agents in their own isolated environments, such as Docker (though Docker containers don’t serve as a security boundary by default without additional hardening). This pushes the responsibility for securing these agents entirely onto developers.
Beyond these implementation challenges, heavy sandboxing for coding agents might not even be practical. For instance, OpenCode doesn’t attempt to implement any sandbox behavior with its coding agent; it operates with full system access from the start, unlike Claude Code. However, in practice, many Claude Code power users and every agentic framework based on Claude Code run it in YOLO mode (–dangerously-skip-permissions) anyway, effectively bypassing whatever sandbox protections exist. This is understandable, as constant permission prompts undermine the automation these tools are designed to provide.
Effective sandboxing for AI coding agents might be fundamentally impossible. Even in a fully sandboxed environment, the agent still needs access to real files. Think API keys, configuration secrets, database connection strings, and proprietary source code.
Furthermore, this challenge extends far beyond software development; lawyers, doctors, and accountants are rapidly adopting AI agents, potentially creating more critical security gaps.
The Lethal Trifecta
This raises a question the security industry hasn’t adequately addressed: How do we balance the isolation necessary for security with the capabilities and tools these agents need to be useful and interact with the world? Simon Willison frames this as the lethal trifecta. If an AI agent can read your private data, encounter attacker-controlled content, and take actions on your behalf, then a malicious instruction hidden in that content can hijack the agent into leaking sensitive information or performing unauthorized actions. The uncomfortable reality is that agents require all three capabilities by design.
Adding to this complexity, every agentic deployment is different, with its own configurations, MCP integrations, plugins, tools, and data sources, making it intractably complex to deterministically assess whether any given system is vulnerable before it executes.
In the absence of any reliable sandboxing methods, adversarial security assessments against your agentic deployment are essential to understanding your actual risk. No two systems share the same attack surface. Only hands-on testing against your AI tooling can cut through the noise and demonstrate real vulnerabilities. At Praetorian, we’re building the offensive agentic AI security practice for this new era.
