AI data exposure rarely looks like a breach. No alerts are triggered, no obvious failure occurs, and most of the time nothing appears to be wrong at all. Instead, sensitive information moves through retrieval, reasoning, and storage layers that were never designed to enforce trust boundaries.
Most organizations evaluate AI systems by reviewing individual components in isolation, even though exposure rarely originates in a single model, tool, or control. It forms in the transitions between them.
This lifecycle review traces how sensitive data escapes during normal system operation, why traditional security controls fail to detect it, and how material risk develops without malicious intent or exploitation.
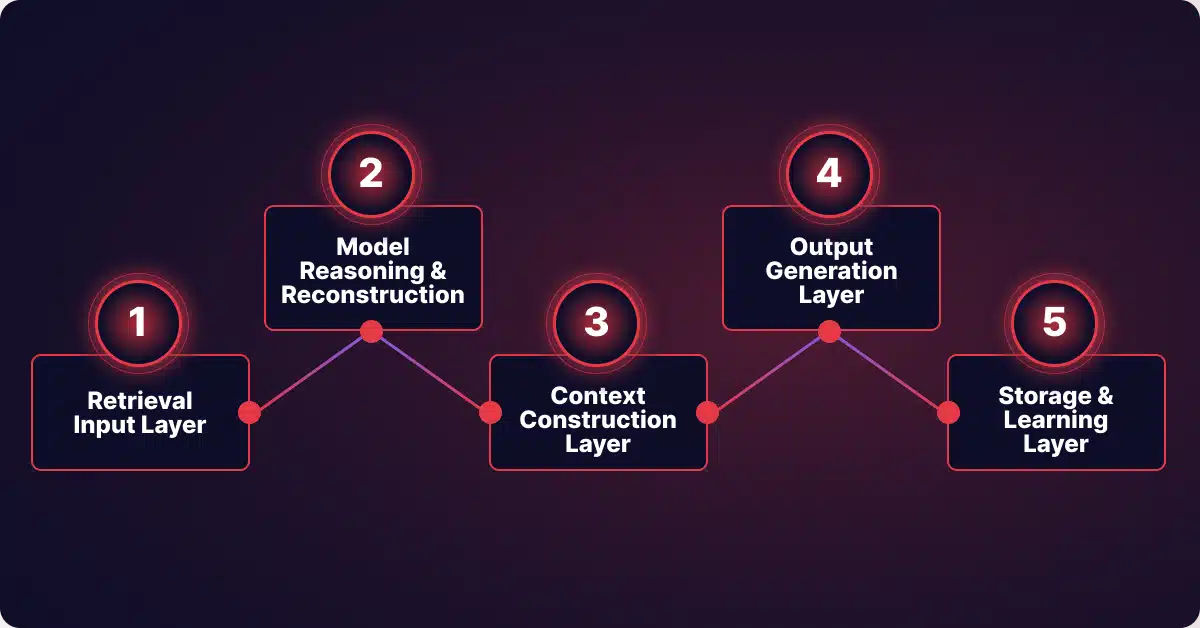
Stage 1: Retrieval Input Layer
Start With Retrieval: Identify Undesigned Access Paths
Exposure often begins with document retrieval. Most AI systems select content using similarity-based scoring, which prioritizes relevance without context for authorization. When public and internal datasets share an index, sensitive material can be pulled into the model’s context simply because it appears relevant to the query.
Key mechanics to review include:
- Whether internal and external sources are indexed together
- Whether authorization checks are enforced before retrieval
- Whether embeddings preserve identifying signals that allow sensitive data to be retrieved or inferred later
If retrieval surfaces internal content, the model will process it.
Failure mode: relevance is evaluated before authorization.
Stage 2: Model Reasoning and Reconstruction
Follow Reconstruction: Assess What the Model Can Infer
Once data enters the model’s context, reasoning introduces the next exposure path. Language models infer missing information using structure, patterns, and correlations, which means partial redaction often provides far less protection than expected.
Risk increases when:
- Redacted fields preserve structure, length, or schema
- Partial identifiers appear elsewhere in the context
- Naming conventions reveal internal structure
If missing data can be reliably inferred, it should be treated as exposed rather than protected.
Failure mode: inferable data is treated as non-sensitive.
Stage 3: Context Construction Layer
Inspect the Prompt Buffer: Locate Where Context Mixing Occurs
Most AI architectures assemble system instructions, user input, retrieved documents, environment metadata, and intermediate outputs into a single prompt. Over time, that prompt becomes a shared workspace rather than a controlled boundary.
Risk increases when:
- System prompts include operational or configuration details
- Environment variables or internal API responses are injected
- Context buffers are reused across agents
- Full prompts are logged verbatim
When multiple trust zones collapse into a single prompt, the model receives information the interface never intended to expose.
Failure mode: trust boundaries are treated as interchangeable.
Stage 4: Output Generation Layer
Test Output Behavior: Determine Whether Internal Context Escapes
Users do not need elevated access to extract internal information. Transformation-based prompts, such as requests to explain reasoning or summarize inputs, are often sufficient.
If internal details appear in output, they were introduced earlier and carried forward through the system.
Failure mode: internal context is assumed to be non-extractable.
Stage 5: Storage and Learning Layer
Trace Data After Execution: Identify Long-Term Exposure Points
Exposure often persists after execution completes. Downstream systems frequently retain sensitive data longer than intended and with fewer restrictions than required.
Common examples include:
- Fine-tuning or Reinforcement Learning from Human Feedback (RLHF) datasets built from real prompts or retrieved content
- Retrieval-augmented generation (RAG) caches without expiration or trust separation
- Logs capturing full prompts and responses
Once sensitive data persists here, exposure becomes durable and difficult to unwind.
Failure mode: data outlives its original trust and purpose
What the Lifecycle Review Reveals
AI data exposure does not require exploitation or malicious intent. It forms when information moves across retrieval, reasoning, context assembly, output generation, and storage layers without enforced trust boundaries. Systems behave normally, controls do not fire, and sensitive data is treated as usable context rather than restricted information.
That is where material risk begins.
Why Praetorian
Praetorian evaluates AI systems by tracing how data actually moves through them. Rather than reviewing components in isolation, we analyze the transitions where trust boundaries break and exposure becomes real.
Those pathways are validated through adversarial reasoning to determine which ones create material risk rather than theoretical concern. The result is engineering-level clarity into where AI systems leak data and what architectural controls are required to prevent it.
For more information, visit praetorian.com.
