At Praetorian, we firmly believe that the most effective way to secure your systems is to look at them through an offensive lens. After all, when you view yourself the same way an attacker does, you get a better understanding of which defenses are likely to be effective. When building Chariot, our External Attack Surface Management solution, we’ve paid a lot of attention to the techniques that have proven most effective during Red Team engagements. One of these high-reward techniques is both easy to execute and highly effective: screenshotting.
Defenders who incorporate this technique for themselves gain the same insight as their attackers do, and often are surprised to discover what assets they have inadvertently shared with the world! In this blog post, we’ll explore why capturing screenshots is an important adversarial technique and how existing tools work today. We’ll also discuss how we’re leveraging machine learning to improve the reliability and speed of parsing the thousands of screenshots we capture every day.
Why screenshots are effective for security evaluation
Given that we have a raft of tools that can work at the source code level, you might wonder why screenshots are an essential part of the Red Team arsenal. After all, isn’t a screenshot much “fuzzier” than the HTML from which it’s constructed? Yes, and this fuzziness is what makes them an interesting adjunct to code-based techniques. Screenshotting is a mainstay technique that provides a starting point for attackers’ more complex manual attacks.
Objectively, writing a tool that detects interesting snippets of HTML is relatively simple to do. That’s exactly how Project Discovery’s excellent nuclei ecosystem works. However, while nuclei excels at detecting certain known things, it has almost no utility against things that are custom to an environment. This is where screenshots come in.
How screenshotting works
The basic idea of screenshotting is that you crawl the entire external attack surface of a company and grab screenshots of all the web resources you discover. Then, you review these screenshots manually. Interesting pages quickly become evident as publicly exposed buckets, internal infrastructure portals, debug output and stack traces, subdomain takeovers, and default application installations become visible.
While a pentester could write signatures to detect some of these vulnerabilities, the span of things in which the pentester might have an interest makes writing deterministic signatures impractical. Reviewing by eye is quicker and more effective. After analyzing the collected screenshots, a Red Team will have a lengthy list of targets they can start working on.
Limitations of existing screenshotting tools
Several well-known tools can collect screenshots in bulk from customer targets. Perhaps the two that will be most familiar to Red Teams are Aquatone and Eyewitness. Both are open-source, free to play around with, and can produce a healthy amount of content. However, none of these existing tools have been able to scale to the volume of data we encounter when conducting external attack surface management with Chariot. Furthermore, none have been able to report their findings with a high enough signal-to-noise ratio.
For perspective, if we crawl just the index pages of the entire external attack surface of a large company using an existing screenshotting tool, we will collect tens of thousands of screenshots. This is too many for a Red Team to completely and carefully review, and so we end up skipping many. If we crawl beyond just the index pages, we will potentially find many more interesting things (misplaced confidential data, etc), but the volume of data will be orders of magnitude greater. When we tried to use existing tools against data at scale, the starting point we gained from screenshotting decreased in utility.
Grouping screenshots to streamline review
We determined that one way to address the scalability problem is by grouping similar screenshots. Instead of a Red Team looking at individual screenshots, they can look at representatives from each group instead. For example, imagine you find a screenshot that looks very interesting security-wise, but isn’t quite exploitable. If you can quickly identify other sites that look similar, you may find a variation that is exploitable, providing a quick win.
Perceptual hashing
In Chariot, our initial grouping mechanism uses perceptual hashing on the collected screenshots. The big idea is to run each screenshot through a specially designed hash function that was designed to give the same hash value for images that a human perceives as similar. With such a hash value for each screenshot, the grouping problem then becomes a simple matter of grouping by equal hash values.
In a 2011 blog post Neal Krawetz provided a detailed explanation of some of the numerous variations on perceptual hashing, but they mostly look the same if you squint:
- Downsize the input image to a fixed size, ignoring aspect ratio (maybe 64×64)
- Convert the image to grayscale
- Convert the image pixel data into frequency domain, by using a discrete cosine or wavelet transform
- Apply a low-pass filter, throwing out high frequencies
- Summarize remaining values with respect to some property of the remaining values, like median value, to produce a fixed-size bitstring
These algorithms work surprisingly well on web page screenshots. By incorporating an off-the-shelf perceptual hash algorithm as part of Chariot’s external Attack Surface Management, we have seen around a 75x reduction in the number of images a Red Team needs to review. That’s a huge reduction!
However, a noticeable amount of redundancy remains, where two screenshots have different perceptual hash values that sort them into separate groups, but a human considers them to be similar. Data-informed estimates suggest a perfect screenshot grouping mechanism would give a further 2–3x reduction in the number of images a Red Team needs to review. This refinement would yield a cumulative 150–225x reduction compared to looking at individual, ungrouped images.
Moving beyond perceptual hashing with machine learning
One fundamental problem with perceptual hashing is that it is a “shallow” function of low-level image features—essentially just pixel intensities. Humans use much higher level features of an image to assess similarity, and this can be difficult to replicate adequately with a simple hash function. Computing these high-level features is a very non-trivial task. This is where machine learning comes in.
Convolutional Neural Networks
Neural networks, especially convolutional neural networks (CNNs), have been a mainstay of computer vision since the 1980s. They played an important role in sparking the deep learning revolution in 2012 when a deep CNN won the ImageNet Large Scale Visual Recognition Challenge by a wide margin. Like all neural networks, CNNs consist of multiple layers, with each layer computing a relatively simple function of the representation computed by the previous layer. The first layer acts on the raw data, which, in the case of images, is the 3-dimensional array of pixels (width × height × color channel).
The fact that CNNs work well for computer vision is no accident—the architecture of CNNs was originally inspired by designs found in the mammalian visual cortex. The type and number of layers within this type of network reflect this inspiration.
Types of layers
Convolution layers and pooling layers are the two types of layers that distinguish CNNs from other neural networks. Convolution layers work by sliding a localized “kernel” operator over the input data that mimics how real cortical neurons respond to stimuli within a localized region of the visual field called the receptive field. Pooling layers act to reduce the dimensionality of the image while also ensuring local translation invariance.
Number of layers
The depth of a neural network refers to how many layers it has. Modern CNNs can have dozens, or even hundreds of layers. Each layer computes progressively higher and higher level representation of the input image starting with simple things like edge detection and moving on to basic shape detection and so on. The high-level features that the deeper layers in a CNN compute are much better suited for vision classification and recognition tasks, which is why these models are so useful.
Using CNN to group screenshots
We reasoned that these representations also would be well suited for ascertaining perceptual similarity. Adapting a perceptual hash function to work off one or more of these representations ought to result in a much better grouping of screenshots than existing tools can achieve using traditional methods.
Identifying interesting screenshots with machine learning
Besides grouping similar images, another use-case for machine learning is to build a model to automatically classify a screenshot as “interesting” from a security perspective or not. Better still, we can have a model rank pages in terms of potential security interest, allowing our Red Team to focus first on the more likely targets. As with perceptual similarity, ranking screenshots in terms of security interest is not something easily done with low-level features, so it makes sense to use a deep CNN model for this task.
To get a sense for how well this might work, we had a team of security engineers rank nearly 10,000 screenshots on a scale from 1 to 5 with 5 being the most interesting. We then took a deep CNN that had been pre-trained on image classification tasks and further trained it to predict the scores our engineers assigned. The lift curve in figure 1 gives some sense of how well the model is doing.
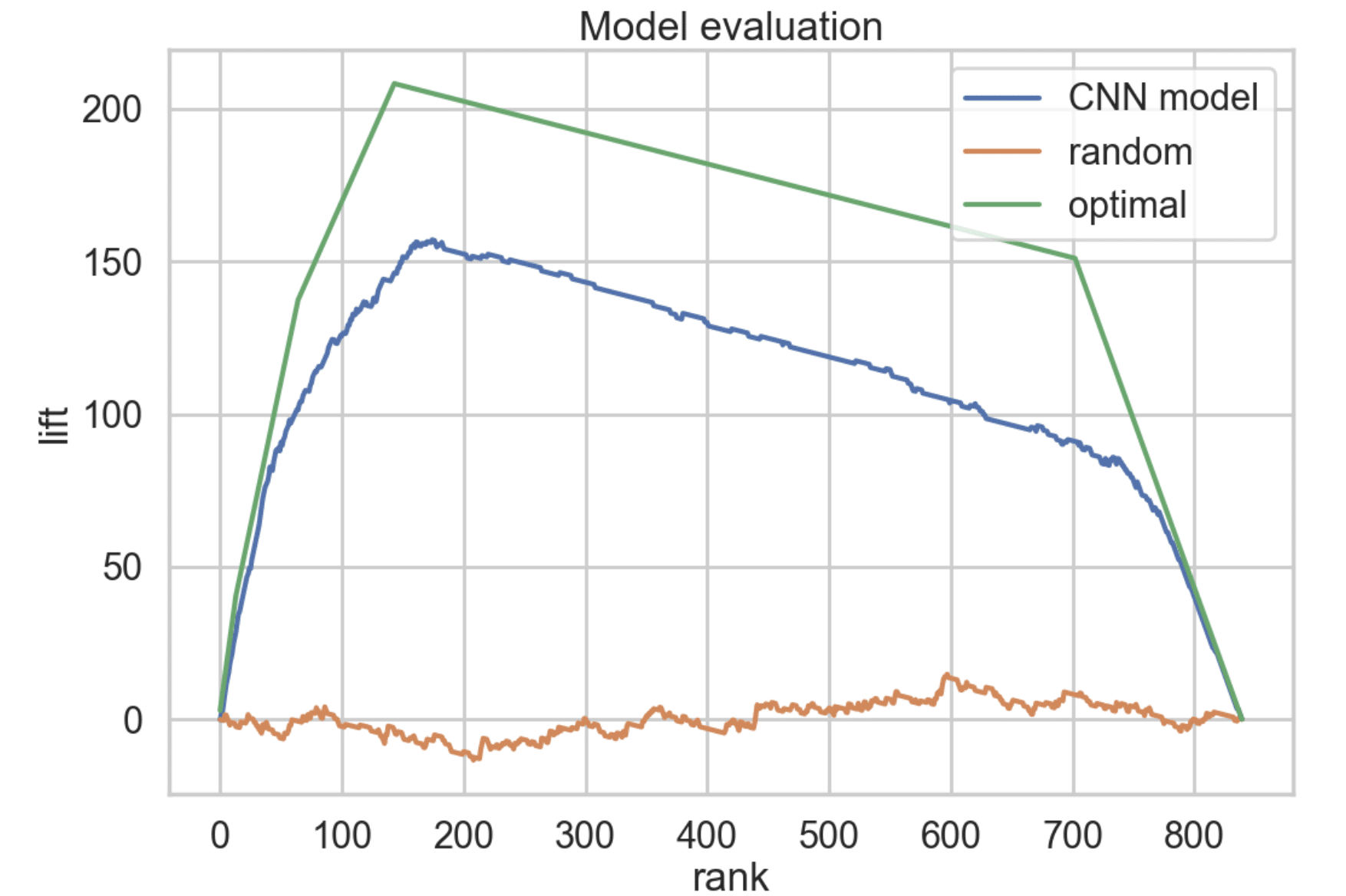
Figure 1: Evaluating how well our model (blue) performs in comparison to optimal (green) and random (orange) models in ranking 840 screenshots not seen during training.
Our tool sorted 840 new screenshots in descending order according to the score assigned by the model. Then it plotted the cumulative sum of the actual (human-assigned) scores (normalized so that the mean score was 0). For reference, the figure shows the corresponding curves for an optimal model (that perfectly predicts the human-assigned score) and a model that assigns scores at random. This diagram demonstrates that the model is doing significantly better than random. Using the area under the curve as a metric, the model is 71.7% of optimal.
Closing thoughts & future work
Collecting and analyzing screenshots has been a mainstay of manual attack surface exploration for years. It is effective and relatively quick. But when you are providing external attack surface management at scale, manual techniques are not the right choice: you need repeatability, predictability, and most importantly, speed.
By embracing modern machine learning techniques, we’re building enhanced capabilities into Chariot. Users of the platform won’t necessarily see the work that’s going on behind the scenes (though Chariot subscribers can quickly pull up screenshots we’ve labeled as “interesting” through our UI). They will, however, see the results showing up as exposures and vulnerabilities.
We certainly have more work to do to improve the machine learning capabilities of Chariot. We would like to build a multi-modal model for analyzing screenshots that looks at not only the screenshot itself but also the underlying HTML and Javascript code. Our goal is pretty simple: to leverage automation – and especially ML – to provide customers with the peace of mind they deserve when it comes to security. Our screenshotting tool work is just another step along that path.
